OpenAI bị diệt vong? – Vân vân, Microsoft?
All eyes are on how long the profitless spending on AI continues. H100 rental pricing is falling every month and availability is growing quickly for medium sized clusters at fair pricing. Despite this, it’s clear that demand dynamics are still strong. While the big tech firms are still the largest buyers, there is an increasingly diverse roster of buyers around the world still increasing GPU purchasing sequentially.
Most of the exuberance isn’t due to any sort of revenue growth, but rather due to the rush to build ever larger models based on dreams about future business. The clear target that most have in mind is matching OpenAI and even surpassing them. Today, many firms are within spitting distance of OpenAI’s latest GPT-4 in Chatbot ELO, and in some ways such as context length and video modalities, some firms are already ahead.
It’s clear that given enough compute, the largest tech companies can match OpenAI’s GPT-4. Gemini 2 Ultra is rumored to surpass GPT-4 Turbo in every way. Furthermore, Meta’s Llama 3 405B is also going to match GPT-4 while being open-source, meaning GPT-4 class intelligence will be available to anyone who can rent an H100 server.
It’s not just the big tech firms that have rapidly caught up. Yesterday, China’s DeepSeek open-sourced a new model that is both cheaper to run than Meta’s Llama 3 70B and better. While the model is more tuned for Chinese language queries (tokenizer / training data set) and government censorship of certain ideas, it also happens to win in the universal languages of code (HumanEval) and math (GSM 8k).
Furthermore, the pricing is incredibly cheap. Deepseek’s model is markedly cheaper than any other competitive model. Their pricing even leapfrogs the ongoing race to the bottom of VCs investing in inference API providers who lose money serving Meta and Mistral models.
DeepSeek claims that a single node of 8xH800 GPUs can achieve more than 50,000 decode tokens per second peak throughput (or 100k prefill in a node with disagg prefill). At the quoted API pricing of output tokens alone, that is $50.4 revenue per node per hour. The cost for an 8xH800 node in China is about $15 an hour, so assuming perfect utilization, DeepSeek can make as much as $35.4 an hour per server, or up to 70%+ gross margins.
Even assuming servers are never perfectly utilized, and batch sizes are lower than peak capability, there is plenty of room for DeepSeek to make money while crushing everyone else’s inference economics. Mixtral, Claude 3 Sonnet, Llama 3, and DBRX were already beating down OpenAI’s GPT-3.5 Turbo, but this is the nail in the coffin.
Even more interesting is the novel architecture DeepSeek has brought to market. They did not copy what Western firms did. There are brand new innovations to MoE, RoPE, and Attention. Their model has more than 160 experts with 6 routed to per forward pass. 236 billon total parameters with 21 billion active per forward pass. Furthermore, DeepSeek implemented a novel Multi-Head Latent Attention mechanism which they claim has better scaling than other forms of attention while also being more accurate.
They trained the model on 8.1 trillion tokens. DeepSeek V2 was able to achieve incredible training efficiency with better model performance than other open models at 1/5th the compute of Meta’s Llama 3 70B. For those keeping track, DeepSeek V2 training required 1/20th the flops of GPT-4 while not being so far off in performance.
These results demonstrate Chinese companies are now competitive as well. Also the paper is probably the best one this year in terms of information and details shared.
While foreign competition is a challenge for OpenAI, their biggest partner is the one they have to watch out for most.
Microsoft is spending over $10 billion in capex directly for OpenAI, but they are not directing most of their GPU capacity to OpenAI. The majority of Microsoft’s planned >$50 billon annual spend on AI datacenters is going to internal workloads. Much of this has been for inference to deploy OpenAI models in their own products and services, but that’s changing.
Microsoft is forced into looking for contingency plans because of OpenAI’s bizarre structure. OpenAI is a non-profit whose primary goal is creating artificial general intelligence (AGI) that is safe and benefits all of humanity. OpenAI can and will break the agreement that enables Microsoft to have access to OpenAI’s models, with zero recourse from Microsoft.
While our partnership with Microsoft includes a multibillion dollar investment, OpenAI remains an entirely independent company governed by the OpenAI Nonprofit. Microsoft is a non-voting board observer and has no control.
AGI is explicitly carved out of all commercial and IP licensing agreements.
The board determines when we’ve attained AGI. Again, by AGI we mean a highly autonomous system that outperforms humans at most economically valuable work. Such a system is excluded from IP licenses and other commercial terms with Microsoft, which only apply to pre-AGI technology.
The most worrisome thing for Microsoft here is that OpenAI’s board can decide at any moment, with no voting input whatsoever from Microsoft, that they have achieved AGI and Microsoft is not entitled to the IP that was created with their investment dollars.
When you stack that on top of the massive governance issues OpenAI has already has related to their non-profit and for-profit arms, Microsoft must put a contingency plan in place.
Microsoft is attempting to move the majority of their inference volumes away from OpenAI’s models to their own models that they developed IP for directly. This includes the Copilot and Bing initiatives that are driving much of Microsoft’s AI story. When OpenAI has the only model capable, of course Microsoft will use it in their products, but otherwise, they will prioritize their own models for the majority of queries.
The question is how?
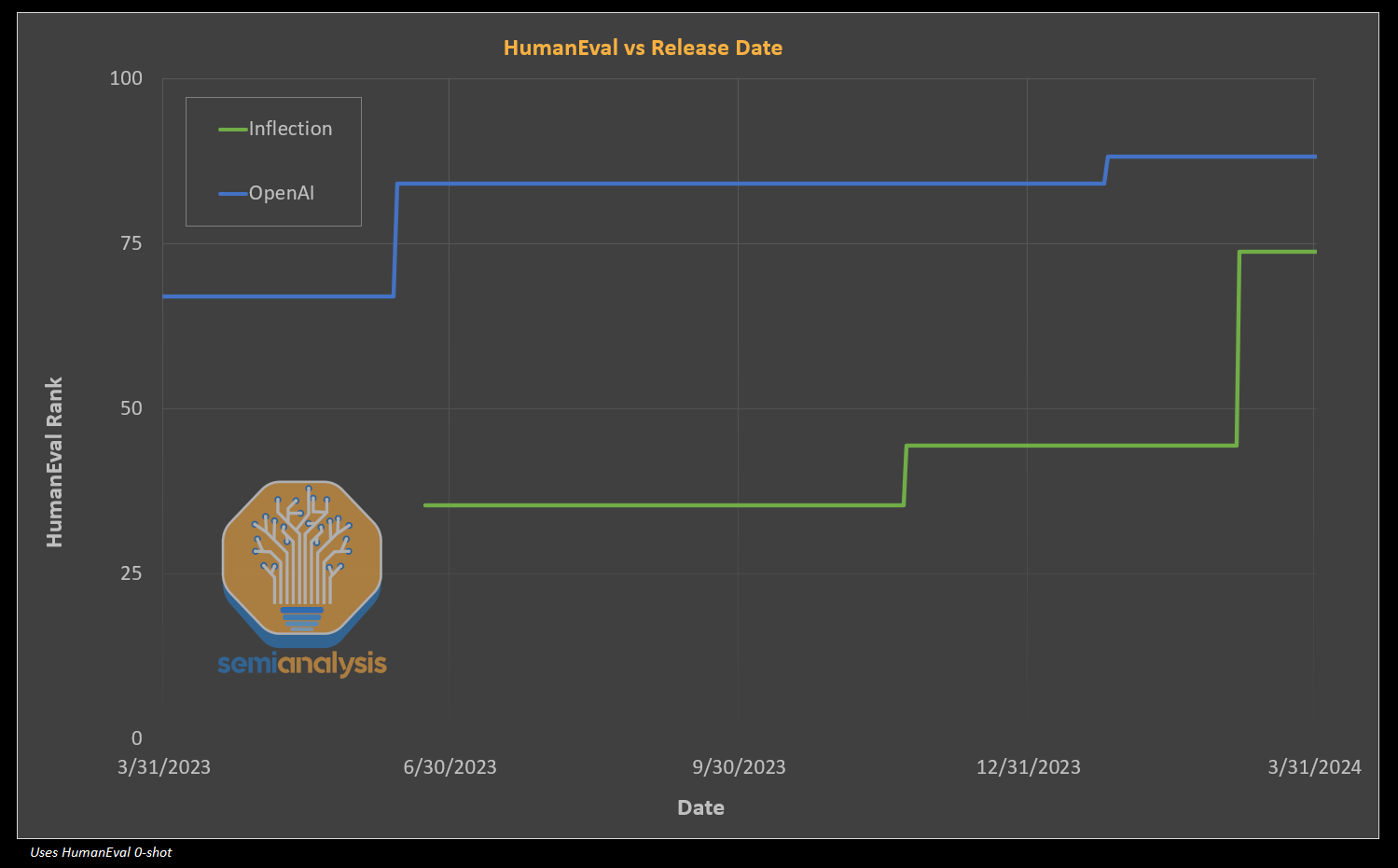
While Microsoft isn’t competitive with OpenAI, or even with Meta in AI talent, they are rapidly attempting to build up those skills as fast as possible. The pseudo-acquisition of Inflection gives them a quick jump to a decent model and a solid pre-training and infrastructure team, but more is needed to close the ever-moving target of OpenAI.
Microsoft already has some strong teams working on synthetic data, which can be considered one of the most important battlegrounds for the next generation of models. The Microsoft Phi model team is well known for training small models with significant amounts of synthetic data from larger models. The latest Phi-3 model release has been seriously impressive. This strategy will work if the goal is to remain only slightly behind OpenAI.
Another team at Microsoft, WizardLM, has created something even more amazing called “Evol-Instruct.” It’s an AI-based method for generating a large diverse sets of instructions for LLMs. The goal is to improve the LLMs’ ability to follow complex instructions without relying on human-created data, which can be expensive, time-consuming, and lack volume/diversity.
Instead, data is being created and curated by AI, to recursively improve itself through simulated chats with itself. The AI will judge quality and iterate to generate better data. It also utilizes progressive learning which changes the data mix, starting off easy and gradually increasing the difficulty and complexity of the training data, so the model can learn more efficiently.
Microsoft’s first big effort at hitting GPT-4 class is currently happening with the MAI-1 ~500B parameter MOE model. It utilizes the Inflection pretraining team and their dataset combined with some of Microsoft’s own synthetic data. The goal is to have their own inhouse from scratch GPT-4 class model by the end of this this month.
We are not sure if it will quite hit the mark, but this MAI-1 initiative is just the start of a long road of aggressive internal modeling efforts. Microsoft has plans for a 100k GPU cluster for their internal team, 5x larger than than the GPT-4 training cluster was.
Many firms use OpenAI’s technology through Azure. More than 65% of the Fortune 500 now use Azure OpenAI service. It’s noteworthy this is not directly through OpenAI. OpenAI can lose significant business without Google Deepmind or Amazon Anthropic gaining share simply by Microsoft pushing their own model instead.
With DeepSeek and Llama 3 405B coming to the open source, there is very little reason for enterprises to not host their own model. Zuckerberg’s strategy of using open-source models to slow down competitions commercial adoption and attract more talent is working wonders. Fine tuning is no longer a monumental task given Databricks is also extremely competent at training better than GPT 3.5 quality generalized models from scratch.
One of OpenAI’s advantages is that they have been ahead in collecting usage data, but that is changing soon enough. This is because both Meta and Google have more direct access to the consumer. Only a quarter of Americans have ever even tried ChatGPT, and most don’t continue to use it. Most future consumer LLM usage will go through existing platforms, Google, Instagram, WhatsApp, Facebook, iPhone/Android.
While Meta hasn’t found out how to monetize it, their Meta AI, powered by Llama 3 70B, is available across Facebook, Instagram, Whatsapp. The announced rollout has been extended to 14 countries including the US, countries totaling 1.1B in population. An incredibly sizeable number of users already have access to better than ChatGPT free models. Meta AI is at the earlier stages of its growth curve and is only 1/3 of the way towards enabling its entire 3.24B daily active user base.
While Llama 3 70B may lack much of the functionality of larger and more capable models – it is likely the right product-market fit for its users among those that are mobile-centric users including many in emerging markets – one would hypothesize such mobile-centric users would probably be making shorter general knowledge queries as opposed to focused high input token agent use cases. Meta’s deployment probably hurts Google Search more than Bing or Perplexity ever will.
To serve up 3B people – you clearly need to have a small and efficient model to bring the cost of inference down. Either Meta has made the financial math work or it is prepared to invest heavily to execute a land grab in the consumer AI space. Either spells disaster for the incumbents.
And it’s not just Meta that is mustering for battle stations – Google has user reach on the same order of magnitude as Meta. If Google strikes a deal with Apple to have its Gemini model served up on the iPhone exclusively, the same strategy Google used to entrench its dominance in the search market over a decade ago will be applied here.
The other argument to be made is if compute and capital are king. In that case, Google is king given their hyper aggressive TPU buildout pace. Ironically, Google now has focus and is directing all large-scale training efforts into one combined Google Deepmind team while Microsoft is starting to lose focus by directing resources to their own internal models that compete with OpenAI.
There is a capital question. At what point does it stop being worth it to put the capital in?
One of the biggest risks for OpenAI is that the capital game is all that matters. If that’s the case, the tech company that invests the most is the winner. While Microsoft is investing the most today, they aren’t that far ahead of Meta, Google, and Amazon/Anthropic. Meta and Google have complete focus while Amazon and Microsoft have to fight with 1 arm tied back due to their lack of control over their allied AI Lab.
Custom silicon is another major point, as it dramatically reduces the cost of compute versus buying Nvidia chips. Microsoft has the least custom AI silicon deployed in their cloud, and that will remain true until at least 2026. Meanwhile, Google, Meta, and Amazon are ramping their internal silicon to varying degrees of volume which gives them a cost of compute advantage.
While the above is a fun exercise in playing devil’s advocate, we don’t believe OpenAI is doomed, in fact this is all just window dressing practicing the bear argument in the leadup to the next generation model which we will briefly discuss below.
