Groq Inference Tokenomics: Tốc độ, nhưng phải trả giá như thế nào?
Groq, an AI hardware startup, has been making the rounds recently because of their extremely impressive demos showcasing the leading open-source model, Mistral Mixtral 8x7b on their inference API. They are achieving up to 4x the throughput of other inference services while also charging less than 1/3 that of Mistral themselves.

Groq has a genuinely amazing performance advantage for an individual sequence. This could enable techniques such as chain of thought to be far more usable in the real world. Furthermore, as AI systems become autonomous, output speeds of LLMs need to be higher for applications such as agents. Likewise, codegen also needs token output latency to be significantly lower as well. Real time Sora style models could be an incredible avenue for entertainment. These services may not even be viable or usable for end market customers if the latency is too high.
This has led to an immense amount of hype regarding Groq’s hardware and inference service being revolutionary for the AI industry. While it certainly is a game changer for certain markets and applications, speed is only one part of the equation. Supply chain diversification is another one that lands in Groq’s favor. Their chips are entirely fabricated and packaged in the United States. Nvidia, Google, AMD, and other AI chips require memory from South Korea, and chips/advanced packaging from Taiwan.
These are positives for Groq, but the primary formula for evaluating if hardware is revolutionary is performance / total cost of ownership. This is something Google understands intimately.
The dawn of the AI era is here, and it is crucial to understand that the cost structure of AI-driven software deviates considerably from traditional software. Chip microarchitecture and system architecture play a vital role in the development and scalability of these innovative new forms of software. The hardware infrastructure on which AI software runs has a notably larger impact on Capex and Opex, and subsequently the gross margins, in contrast to earlier generations of software, where developer costs were relatively larger. Consequently, it is even more crucial to devote considerable attention to optimizing your AI infrastructure to be able to deploy AI software. Firms that have an advantage in infrastructure will also have an advantage in the ability to deploy and scale applications with AI.
Google AI Infrastructure Supremacy: Systems Matter More Than Microarchitecture
Google’s infrastructure supremacy is why Gemini 1.5 is significantly cheaper to serve for Google vs OpenAI GPT-4 Turbo while performing better in many tasks, especially long sequence code. Google uses far more chips for an individual inference system, but they do it with better performance / TCO.
Performance in this context isn’t just the raw tokens per second for a single user, i.e. latency optimized. When evaluating TCO, one must account for the number of users being served concurrently on hardware. This is the primary reason why improving edge hardware for LLM inference has a very tenuous or unattractive tradeoff. Most edge systems won’t make up for the increased hardware costs required to properly run LLMs due to such edge systems not being able to be amortized across massive numbers of users. As for serving many users with extremely high batch sizes, IE throughput and cost optimized, GPUs are king.
As we discussed in the Inference Race to the Bottom analysis, many firms are genuinely losing money on their Mixtral API inference service. Some also have very low-rate limits to limit the amount they lose. We dove deeper into quantization and other hardware GPU options such as MI300X in the report, but the key takeaway is those serving an unmodified model (FP16) required batch sizes of 64+ to turn a profit. We believe that Mistral, Together, and Fireworks are serving Mistral at breakeven to slight profit margins.
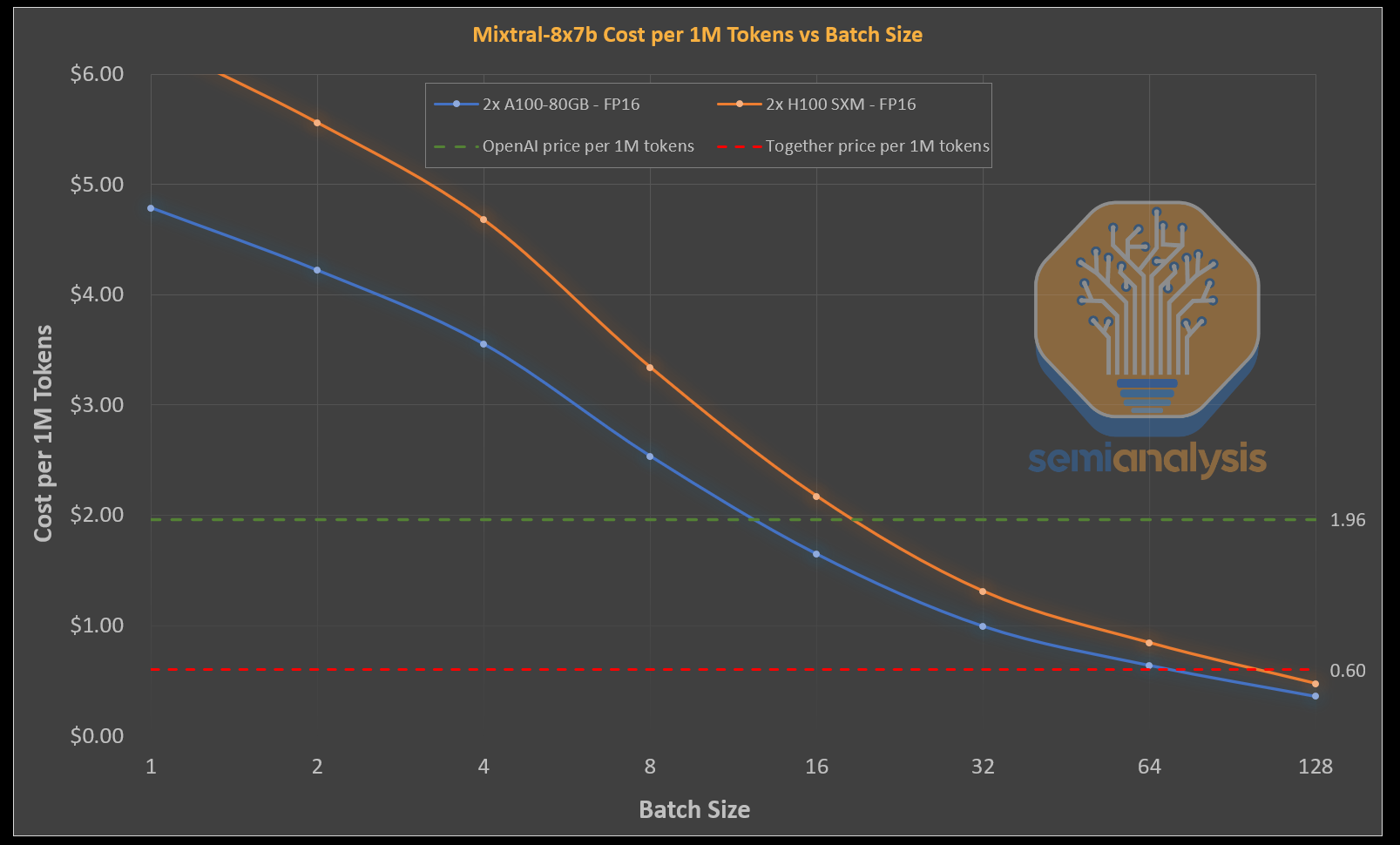
The same cannot be said for others offering Mixtral APIs. They are either lying about quantization, or lighting VC money on fire to acquire a customer base. Groq, in a bold move, is matching these folks on pricing, with their extremely low $0.27 per million token pricing.
Is their pricing because of a performance/TCO calculation like Together and Fireworks?
Or is it subsidized to drive hype? Note that Groq’s last round was in 2021, with a $50M SAFE last year, and they are currently raising.
Let’s walk through Groq’s chip, system, a costing analysis, and how they achieve this performance.
Groq’s chip has a fully deterministic VLIW architecture, with no buffers, and it reaches ~725mm2 die size on Global Foundries 14nm process node. It has no external memory, and it keeps weights, KVCache, and activations, etc all on-chip during processing. Because each chip only has 230MB of SRAM, no useful models can actually fit on a single chip. Instead, they must utilize many chips to fit the model and network them together.
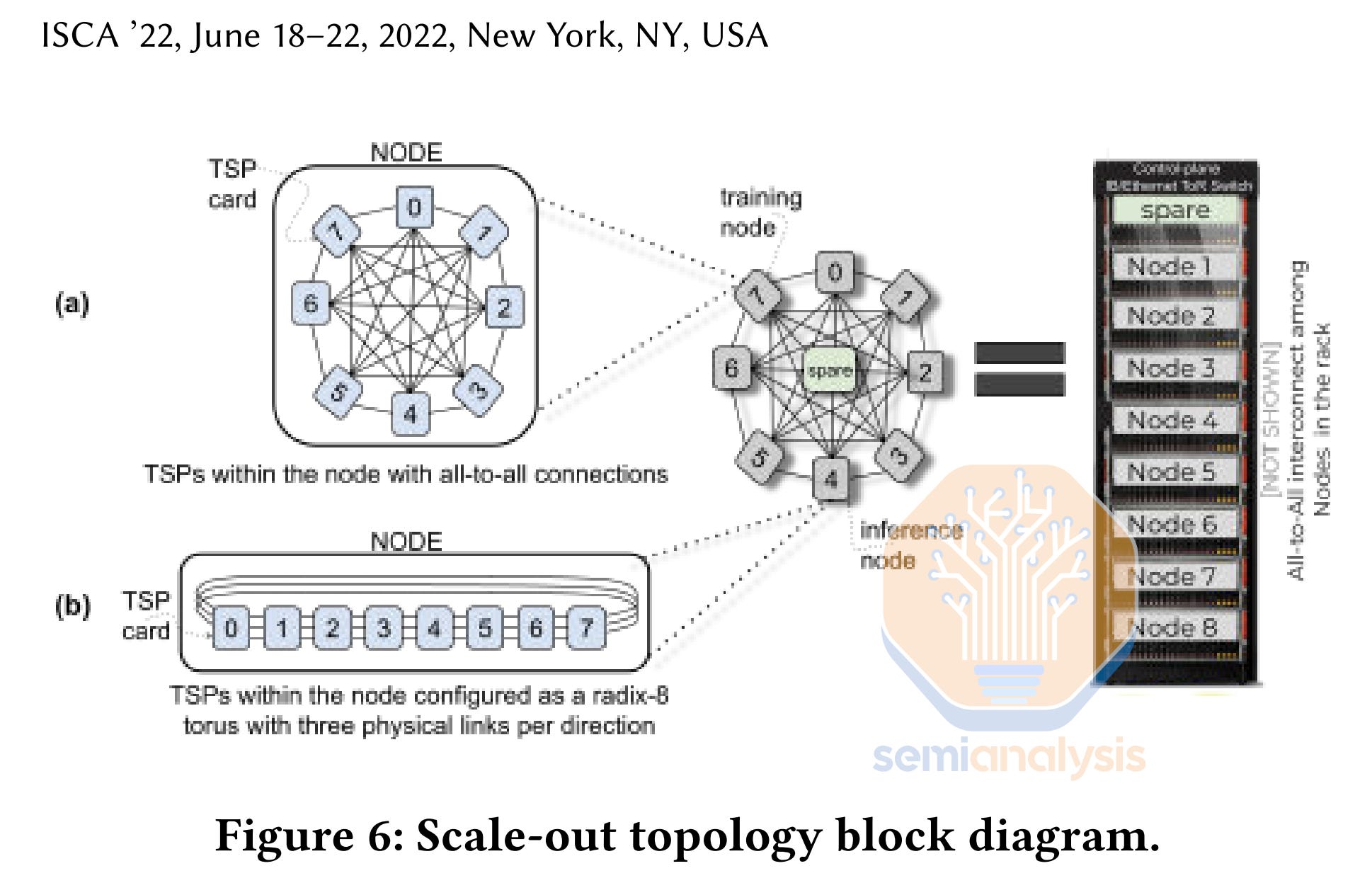
In the case of the Mixtral model, Groq had to connect 8 racks of 9 servers each with 8 chips per server. That’s a total of 576 chips to build up the inference unit and serve the Mixtral model. Compare that to Nvidia where a single H100 can fit the model at low batch sizes, and two chips have enough memory to support large batch sizes.
The wafer cost used to fabricate Groq’s chip is likely less than $6,000 per wafer. Compare this to Nvidia’s H100 at 814mm2 die size on a custom variant of TSMC’s 5nm called 4N. The cost for these wafers is closer to $16,000 per wafer. On the flip side, Groq’s architecture seems less viable for implementing yield harvesting versus Nvidia’s, who has an extremely high parametric yield, due to them disabling ~15% of die for most H100 SKUs.
Furthermore, Nvidia buys 80GB of HBM from SK Hynix for ~$1,150 for each H100 chip. Nvidia also has to pay for TSMC’s CoWoS and take the yield hit there, whereas Groq does not have any off chip memory. Groq’s raw bill of materials for their chip is significantly lower. Groq is also a startup, so they have much lower volume/higher relative fixed costs for a chip, and this includes having to pay Marvell a hefty margin for their custom ASIC services.
The table below presents three deployments, one is for Groq, with their current pipeline parallelism and with batch size 3, which we we hear they will implement in production next week, and the others outline a latency optimized H100 inference deployment with speculative decoding as well as a throughput optimized H100 inference deployment.

The table above greatly simplifies the economics (while ignoring significant amounts of system level costs which we will dive into later, and it also ignores Nvidia’s massive margin). The point here is to show that Groq has a chip architectural advantage in terms of dollars of silicon bill of materials per token of output versus a latency optimized Nvidia system.
8xA100s can serve Mixtral and achieve a throughput of ~220 tokens per second per user, and 8xH100s can hit ~280 tokens per second per user without speculative decoding. With Speculative decoding, the 8xH100 inference unit can achieve throughputs approaching 420 tokens per second per user. The throughput could exceed this figure, but implementing speculative decoding on MoE models is challenging.
Latency optimized API services currently do not exist because the economics are so bad. The API providers currently do not see a market for charging 10x more for lower latencies. Once agents and other extremely low latency tasks become more popular, GPU based API providers will likely spin up latency optimized APIs alongside their current throughput optimized APIs.
Latency optimized Nvidia system with speculative decoding are still quite far behind on throughput and costs versus Groq without speculative decoding, once Groq implements their batching system next week. Furthermore, Groq is using a much older 14nm process technology and paying a sizable chip margin to Marvell. If Groq gets more funding and can ramp production of their next generation 4nm chip, coming in ~H2 2025, the economics could begin to change significantly. Note that Nvidia is far from a sitting duck as we think they are going to be announcing their next generation B100 in less than a month.
In a throughput optimized system, the economics change significantly. Nvidia systems attains an order magnitude better performance per dollar on a BOM basis, but with lower throughput per user. Groq is not competitive architecturally at all for throughput optimized scenarios.
However, the simplified analysis presented above isn’t the right way to look at the business case for people that are buying systems and deploying them, as that analysis ignores system costs, margins, power consumption, and more. Below, we present a performance / total cost of ownership analysis instead.
Once we account for these factors, the Tokenomics (cred swyx for swanky new word), look very different. On the Nvidia side we will use the GPU cloud economics explained here and shown below.

Nvidia applies a huge gross margin to their GPU baseboards. Furthermore, this $350,000 price charged for the server, which is well above the hyperscaler cost for an H100 server, also includes significant costs for memory, 8 InfiniBand NICs with aggregate bandwidth of 3.2Tbps (not needed for this inference application), and a decent OEM margins stacked on top of Nvidia’s margins.
For Groq, we are estimating system costs and are factoring in details regarding the chip, package, networking, CPUs, memory, while assuming a lower overall ODM margin. We are not including Groq’s margin charged for selling hardware either, so while it may seem Apples vs Oranges, it’s also a fair comparison of Groq’s cost vs an Inference API provider’s costs, as both are serving up the same product/model.

It’s noteworthy that 8 Nvidia GPUs only need 2 CPUs, but Groq’s 576 chip systems currently have 144 CPUs, and 144TBs of RAM.
