Faster post–silicon analysis with an AWS data lake – AWS Blog
Manufacturing semiconductor devices using advanced nodes have many challenges, but perhaps none is more directly linked to the company’s profitability and competitive position than yield. Yield improvements directly reduce the cost of manufacturing a single die while also helping the company amortize the development costs across more dies.
There are great commercial products helping customers do most of the work in terms of yield improvement (such as from PDF Solutions and NI). The purpose of this blog is not to encourage you replace them, but rather to augment them. Building a modern data lake architecture can help you analyze and visualize data faster to drive faster data-driven insights. More customers are building custom data pipelines to answer new types of questions resulting from the use of advanced nodes, chiplets, 3D stacking or experimenting with new yield improvement methods.
Automatic test equipment (ATE) produces files in the Standard Test Data Format (STDF) specification. STDF dates back to 1985, and its latest release (version 4) is from 2007. Modern data analysis tools, that were designed to process data in parallel, were not considered when the standard was developed.
The file structure is similar to XML in many ways:
The first challenge we come across when building a post–silicon analysis data lake is transferring data into the environment running on AWS. Each manufacturing partner has a specific way of sharing files: some permit only Secure File Transfer Protocol (SFTP) uploads, and some permit only Secure Hypertext Transfer Protocol (HTTPS) uploads. Others still place the data on a virtual machine (VM) outside their network and expect their customer to connect to the VM and get the data out securely.
Amazon Simple Storage Service (Amazon S3)—object storage built to retrieve any amount of data from anywhere—is a good starting point for your data pipeline as it offers several ways to move data in to AWS from manufacturing partners. For SFTP/File Transfer Protocol Secure (FTPS), AWS Transfer Family provides a fully managed service that lets you easily manage and share data with simple, secure, and scalable file transfers, and it delivers your STDF files to an Amazon S3 bucket. For HTTPS connections and remote desktop scenarios, the AWS Command Line Interface (AWS CLI) facilitates a simple interface to periodically upload data over HTTPS into your Amazon S3 bucket with minimal code writing. The AWS software development kit (SDK) offers support for additional programming languages in case some business logic/pre-processing is required.
The hierarchal data coming in is designed to be space efficient, because it was designed at a time when capacity came at a premium. Modern data analysis tools are designed for processing speed, and for that, the data needs to move from a hierarchal structure to a flat one, so data can be processed in parallel.
Rather than having data spread across multiple different records, we need to combine all data into one record at each level (part, wafer, test).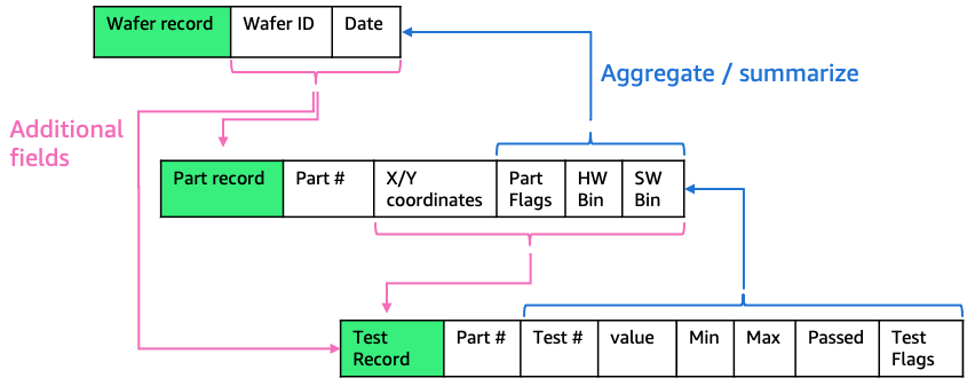
Having all the fields that apply to a specific part in one record allows faster parallel processing. For example, imagine you want to search all tests with a failure rate higher than 10 percent in all wafers that had yield below 80 percent and map them to their X/Y coordinates on the wafer. In the original dataset, that would require large join operations between multiple datasets, taking longer to get the results. Now, all these data fields are in the “test records” dataset and could be processed in parallel, which means faster time to results for the engineer.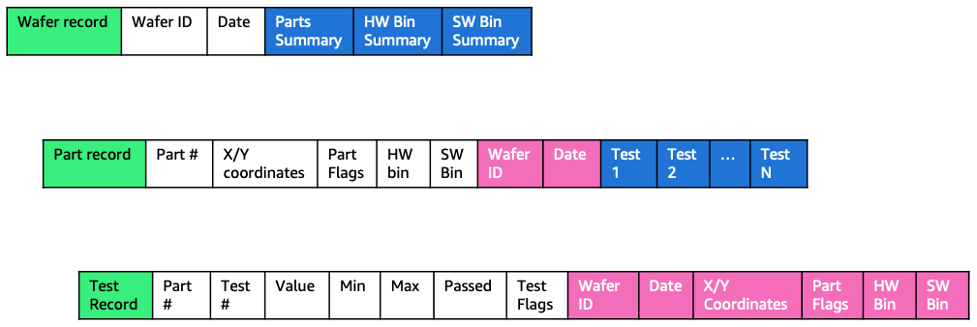
Now that the data structure is more optimal for processing, we want to give our post–silicon teams fast access to the data and an interactive business intelligence (BI) tool to query the data and drive new insights. Amazon QuickSight is a cloud-scale, fully managed BI service that lets users generate new reports and insights. Amazon QuickSight supports various AWS data sources, which enables post–silicon teams to quickly process and analyze their data with low-code/no-code solutions.
Using fully managed services minimizes the need to maintain multiple tools for your data pipeline. They also facilitate greater flexibility to ask new questions because new tools can be added quickly when needed. If the new tool provides the value needed, you can scale as needed. If it doesn’t provide the expected value, you can quickly decommission it and avoid additional costs.
Image 3 shows a wafer map generated from an open-source STDF file, showing how dies in different X/Y positions mapped to individual hardware bins.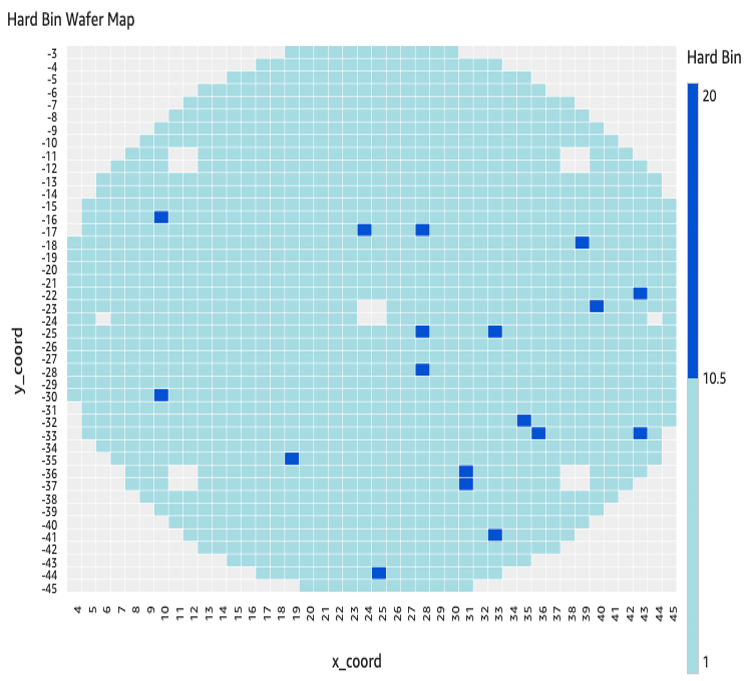
To demonstrate how quickly post–silicon data can be visualized in AWS, we’ve created this sample solution in Image 4. Data is transferred using the method preferred by your manufacturing partner, using the AWS CLI, AWS Transfer Family, or manual uploads. From there, it is stored in the input Amazon S3 bucket, where costs can be further optimized using Amazon S3 storage classes. The upload triggers an AWS Lambda function that will launch a temporary Amazon Elastic Compute Cloud (Amazon EC2) instace to convert the STDF file into multiple comma-separated values (CSV) files (wafer data, part data, test data, and so forth) with a flat data structure (see image 1). Data is stored in the output Amazon S3 bucket, which will grow to serve as the post–silicon data lake. Because the data is unstructured (CSV), we use AWS Glue, a serverless data integration service, to crawl the data and build a date catalog so that data can be queried more efficiently. The data can then be queried using an SQL syntax in Amazon Athena (a serverless, interactive analytics service) or visualized in Amazon QuickSight (as seen in Image 3). The dashboards generated in Amazon QuickSight can then be shared with other users on the team and embedded in webpages.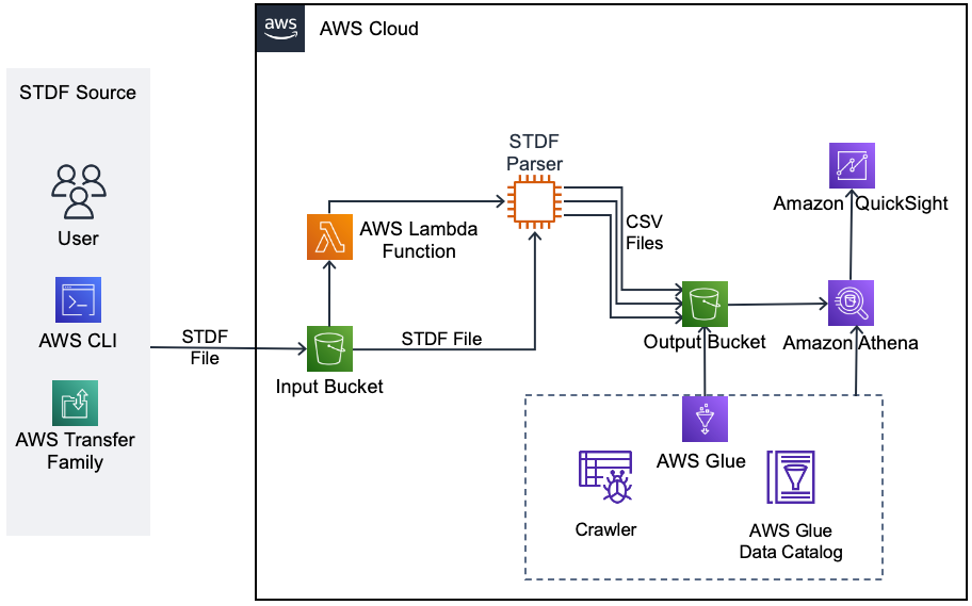
As we mentioned in the beginning, this solution augments existing commercial solutions. You can augment your data lake with data from a commercial solution by exporting it into the data lake. This will allow you to run a single query across the two datasets.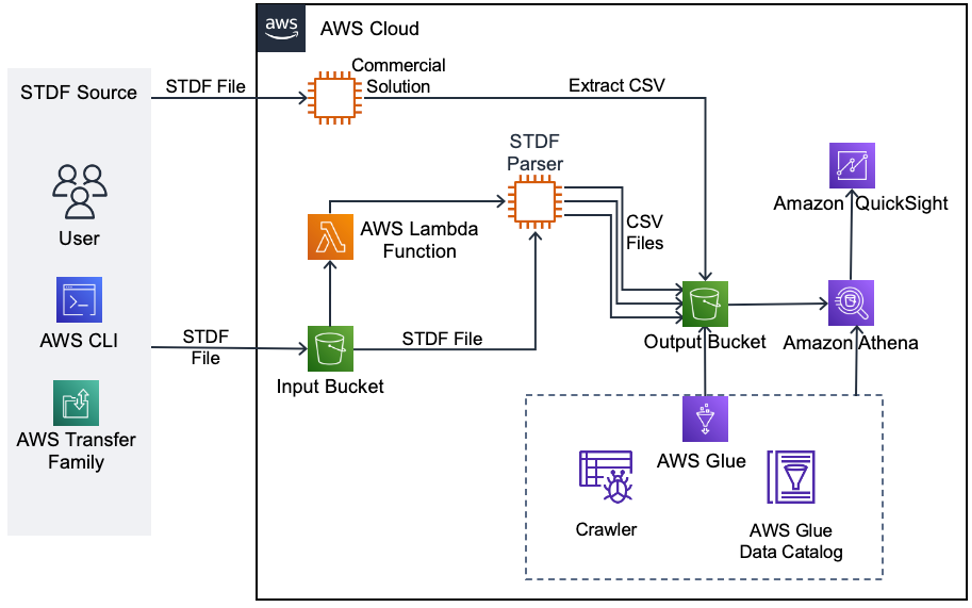
You can see a working environment in the demo video. Although this is a simple workflow, it is meant to show how quickly and interactively your STDF data can be visualized on AWS.
The data lake we built here is not the end of your data pipeline—it’s only the beginning. You can use AWS data analytics services to transform large datasets into actionable insights. Other AWS purpose-built analytics services are already fully integrated with Amazon S3 to facilitate faster analysis and include the following: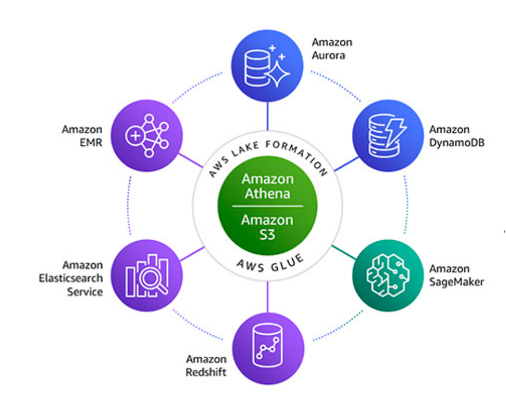
Ramping up yield requires advanced data analysis. Building a modern data lake architecture for your post-silicon engineers will enable them to generate more data-driven insights, and find new possibilities within their existing commercial solutions. It also introduces much needed control over your data pipeline without the administrative overhead required to maintain various data analytics solutions.
To learn more about data analytics on AWS, see Analytics on AWS.
Eran Brown is a senior semiconductor Specialist Solution Architect. He spent 7 years working with semiconductor companies designing HPC storage infrastructure, and after all these years is still amazed at what a square inch of silicon can do.
Sharon Haroz is a senior sales specialist for analytics and ML at AWS based in Tel Aviv. She has more than 20 years of experience helping customers use the power of data to bring value and grow their business. Family, humor, and data are the pillars of her life.