Cuộc đua suy luận đến đáy – Tăng về số lượng?
There are now five companies besides OpenAI that have models that can beat GPT-3.5 in a variety of benchmarks: Mistral Mixtral, Inflection-2, Anthropic Claude 2, Google Gemini Pro, and X.AI Grok. More amazingly, both Mistral and X.AI achieved these stellar results with a team of less than 20 people. Additionally, we also expect Meta, Databricks, 01.AI (Yi), Baidu, and Bytedance to also hit >GPT 3.5 performance very soon. Of course, that’s in benchmarks, and a couple of these folks allegedly train on eval… but never mind that small detail.
For those keeping score, there will be a total of 11 firms in just a handful of months from now. It’s clear that pre-training of a GPT-3.5 caliber model has become completely commoditized. OpenAI is still the king of the hill with GPT-4, but that lead has been compressed significantly. While we believe that most of the long-term value will be captured by the highest-end models, it’s also clear that the next tier down in model quality and cost will enable a multi-billion-dollar niche in the marketplace, especially when fine-tuned.
But who can actually make money off these models if they are everywhere?
Firms with unique distribution due to direct access to the customer via a full software as a service or social media will have a unique advantage. Firms that offer full training or fine-tuning services for others on proprietary data by helping them with every stage of the process from data to serving will have a unique advantage. Firms that can provide data protections and ensure that all model use is legal, will have a unique advantage. Firms that simply serve open models will not have a competitive advantage.
Some of these advantages are exemplified by Microsoft’s Azure GPT API versus OpenAI’s. Microsoft drives larger inference volume for both public and private instances than OpenAI’s own API. The security, data guarantees, and service contract bundling you get with Microsoft is very important to risk-averse enterprises. Furthermore, these protections enable bad actors to more easily get away with improper use as shown by ByteDance’s use of Azure GPT-4 to train their upcoming LLMs.
The reality is that if you aren’t the market leader, you will have to adopt a loss leader strategy to win over business. Google is giving away 60 API requests a minute for free on Gemini Pro, their GPT-3.5 competitor. Google is not unique in that they are subsidizing their would-be customers. In fact, today, almost everyone is losing money on LLM inference.
Serving purely open models is completely commoditized. The capital requirements for offering an inference service are not that large initially, despite being the bulk of spend for any scaled service. There’s dozens of second rate clouds that offer great pricing (mostly because they have questionable assumptions for return on invested capital), but you have to be okay with the potential security risks.
It’s quite trivial for firms to rent some GPUs and start utilizing libraries such as vLLM and TensorRT-LLM to serve open-source models on both Nvidia and AMD GPUs. PyTorch is also starting to get very fast for inference, and thus, the barrier to entry keeps on plummeting. As a related aside, check out the intense, public slap fight between Nvidia and AMD on LLM inference performance between MI300 and H100. AMD’s response back was quite embarrassing for Nvidia, who originally posted a misleading blog post.
With the release of Mistral’s Mixtral, there has been a complete race to the bottom on inference costs, which has primarily been funded by startups burning venture capital money in the hopes of achieving scaled volumes. OpenAI’s GPT-3.5 Turbo model is quite a bit cheaper to run than Mixtral inherently, and OpenAI has quite strong margins primarily driven by their ability to achieve very high batch sizes. This high batch size is a luxury that others with a smaller user base do not have.
OpenAI charges $1.00 per million input tokens and $2.00 per million output tokens. Mistral, despite having a more expensive to run, but higher quality model, must price lower than OpenAI to drive customer adoption. As such, Mistral charges $0.65 per million input tokens and $1.96 per million output tokens. They are effectively a price-taker, as this pricing is largely driven by market forces as opposed to Mistral’s cost of running inference and targeted return on invested capital. Note the performance figures below are based on what custom inference stacks get to on existing models, not TensorRT-LLM or vLLM which are still unoptimized as per our discussions with high volume deployers. Mistral has not yet developed a custom highly optimized inference stack, so their performance is even worse than the below.
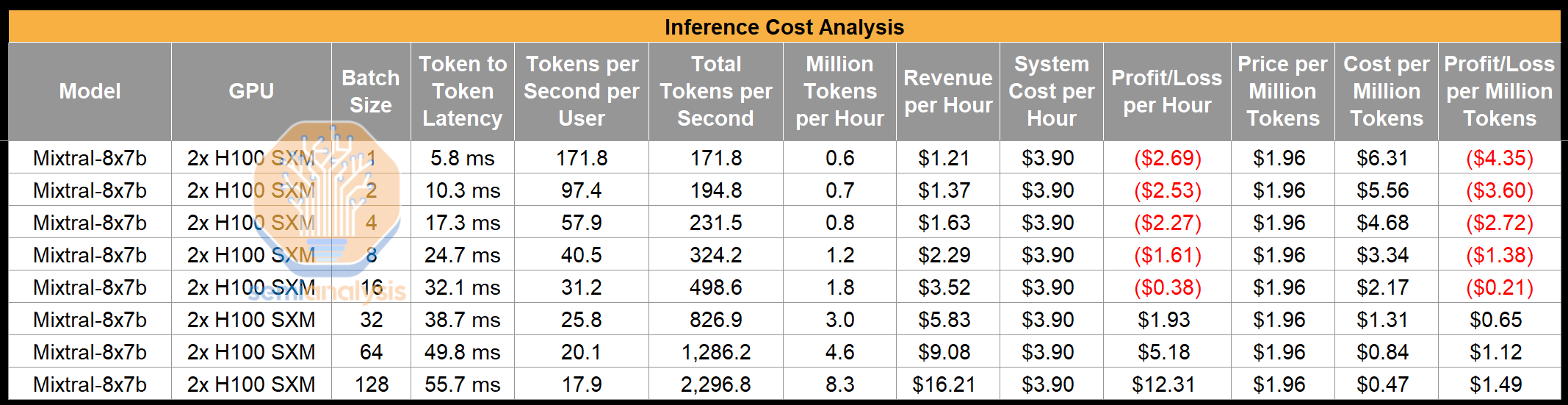
We will get into more detail later with these numbers below, but the high level point is that even in an extremely optimistic scenario, with 2x H100 at BF16 assumed to be always loaded 24/7, at $1.95 an hour per GPU, Mistral barely squeaks by using quite a high batch size. Of course, you can just test the API and see that the reasonably high token throughput implies they are not using such high batch sizes, so it appears to be highly likely that their API is a loss leader, as it would logically have to be to acquire customers against a formidable incumbent. Mistral’s mid-term goal is likely to hopefully drive volume and eventually become profitable on it with cost reductions from hardware/software.
Not to be shown up by Mistral though, everyone and their mother has rushed to offer inference services for the Mixtral model at lower and lower prices. Every few hours, a new company has been announcing pricing. First Fireworks.ai, with $1.60 per million tokens output, $0.40 per million input. Then Together, with $0.60 output, no input cost, then Perplexity at $0.14 input / $0.56 output, neets.ai at $0.55 output, Anyscale $0.50 output. Finally Deepinfra came with $0.27 output… We thought the game was over… but then OpenRouter came out with it for free! To be clear, the tokens per second numbers they present are literally impossible to achieve, and impose such stringent rate limits that you can barely test it.
All of these inference offerings are losing money today.
We should note the 2x H100 is actually not the best system for inference of the Mixtral model. In fact 2x A100 80GB is more cost effective due to its ~32% greater bandwidth per dollar, assuming a similar memory bandwidth utilization rate. The significantly lower FLOPS of the A100 don’t affect inference performance that much either. Note that there is effectively no scenario in which even 2xA100s can make money at the collapsed pricing levels. Later in this report, we will also show the huge benefits H200 and MI300X bring for inference.

Because Mixtral is a mixture of experts model, it operates very differently as you increase the batch size. At batch size 1 only a small portion of the parameters activate per forward pass, giving the model much stronger capabilities at much lower bandwidth and FLOPS per token. This best-case scenario only rings true if you run a batch of size 1 and have enough memory capacity to fit the model.
As you increase batch size though, more of the model experts will be activated, forcing the entire model’s parameters across all experts to be read in for every forward pass. Meanwhile, every decode token still only passes through two experts. As such, MoE models such as Mixtral and GPT-4 are even more bandwidth intensive than dense models.
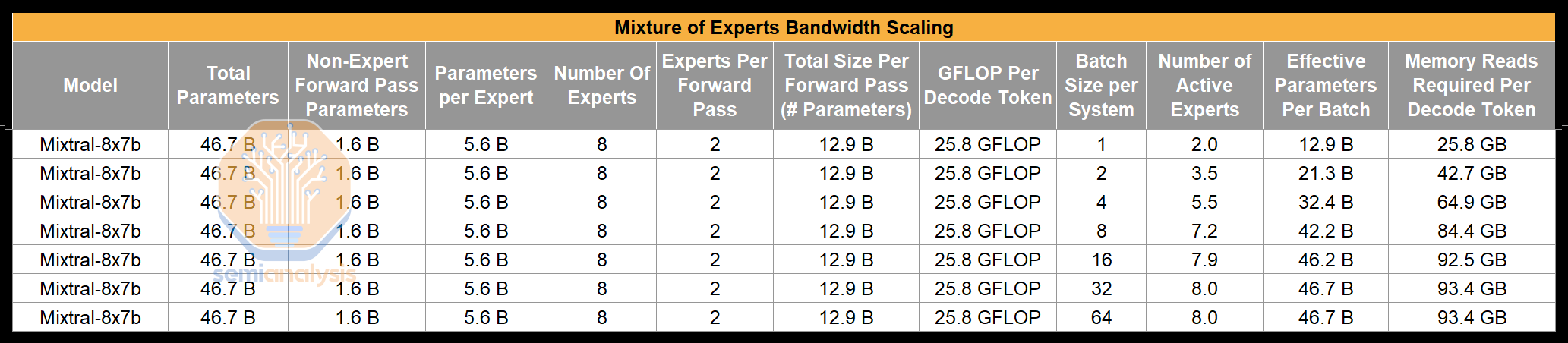
This has huge implications for LLM inference because costs scaling differs significantly as compared to dense models. In short, for MoE models, higher batch sizes, while still reducing costs, don’t reduce costs as much as they do with dense models, due to the increase in memory bandwidth required. This is one of the primary reasons why the foundation models can’t just keep stacking on more and more experts forever. At scale inference costs should always be at high batch sizes, but that doesn’t get you as much benefit with MoEs as for dense models.
Given Together clearly has the best inference engine of the race to the bottom group above in terms of reliability of time to first token, highest tokens per second, no artificially low rate limits, and a steadfast commitment to not silently quantize models behind people’s backs unlike other providers, we wanted to dive into their solution as the base line offering.
We profiled their playground and API over the last handful of days. We were able to peak at ~170 tokens per second per sequence with the temperature set to 0 and a very predictable long sequence. On the other hand, with similarly long but difficult queries with a temperature of 2, we only hit ~80 tokens per second.
Note that both these figures are usually far worse than mentioned above because Together is actually serving a great number of users and is achieving somewhat decent batch sizes. The tokens per second figures numbers above are trying to show a best case, low batch size scenario. Our model indicates that Together is better off using a 2xA100 80GB system rather than an H100 based system. The temperature and performance testing also point to Together utilizing speculative decoding.
We’ve written more detailed notes about speculative decoding before, but as quick recap, speculative decoding is when you run a small, fast draft model in front of a big slow model you would otherwise be running. The draft model feeds a variety of predictions into the larger, slower reviewer model, generating multiple tokens ahead. The large model then reviews all of these look-ahead predictions at once instead of having to auto regressively generate every token on its own. The reviewer model either accepts one of the draft model’s suggestions, enabling the generation of multiple tokens at time, or rejects the suggestions and generates one token as per normal.
The entire point of speculative decoding is to try to reduce the memory bandwidth required to generate each token. Unfortunately, speculative decoding style techniques do not improve performance as much on mixture of experts models like Mixtral because as you increase batch size, your memory bandwidth requirements also go up due to the fact that draft models’ various suggestions will route to different experts. In a similar vein, prefill tokens are relatively more expensive on a mixture of experts model than they are on a dense model.
Back to the temperature point mentioned above. Temperature for LLMs is effectively a creativity or randomness input slider. The reason we tested with low and high temperature scenarios is because the draft model is much more likely to correctly generate tokens that the reviewer model will accept at low temperatures. However, in a high temperature scenario, the reviewer model ends up being more erratic, so the draft model rarely ever guesses the current tokens ahead of time. Modification of temperature is one of many tricks used to try to measure the real tokens per second of a model, because otherwise, clever tricks such as speculative decoding will mess up any reverse engineering or profiling attempts.
While quantization is going to massively improve speed and cost for running these models, huge quality losses will result from quantization if there isn’t a great deal of care applied. Generally, you must fine tune after quantizing a model like this, and indeed at present, some of the low cost race to the bottom type suppliers are not doing such fine tuning. They are instead half-heartedly quantizing with no care for accuracy. If you try out some of these race to the bottom type providers, their model does not generate good outputs like the 16 bit Mixtral model does.
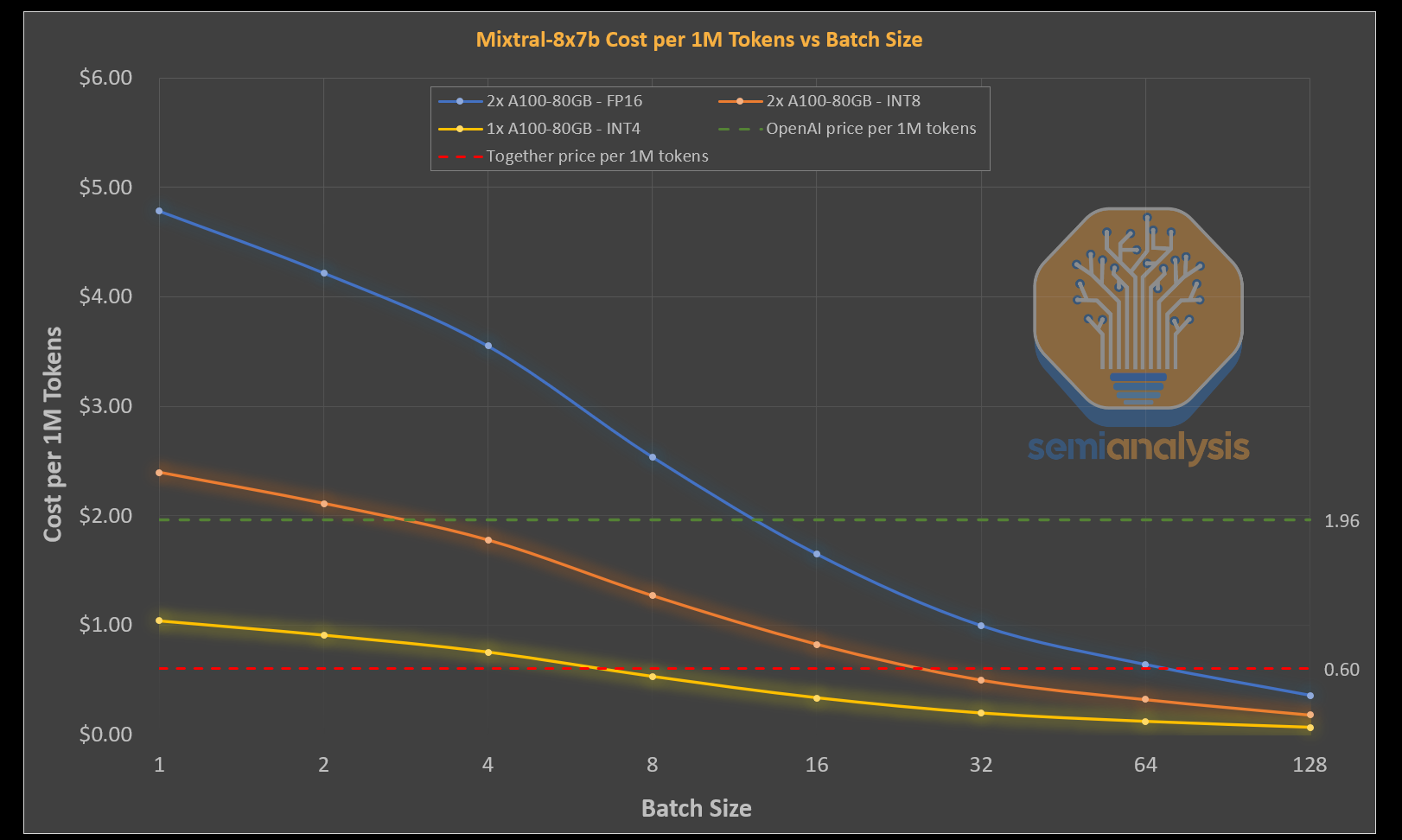
We generally believe researchers will be able get FP8 for inference to work without killing quality, but we don’t think they will be able to get inference to work on INT4 on these very large models. Furthermore, FP8 would still require 2 GPUs using the H100 and/or A100 due to the total tokens per second throughput being well below the ~40-50+ users require for most chat style applications and given KVCache size limitations.
The upcoming H200 and MI300X change this. They have 141GB and 196GB of memory respectively as well as significantly higher memory bandwidth than the H100 and A100. The cost per token for the H200 and MI300X compare far more favorably in our model against the incumbent A100 and H100s. We see huge benefits in moving away from tensor parallelism, given how bad the current NCCL implementation from Nvidia is for all-reduce.
Below, we will share what each system can do on a cost basis. Note that these systems are only starting to be deployed. We are assuming that a highly optimized custom inference stack as exists at some major providers using an H100-based system. Currently, neither Nvidia’s closed source TensorRT-LLM nor AMD’s somewhat more open vLLM integration strategy provides this directly today, but we expect them to over time.