AWS Adopts Arm V2 Cores For Expansive Graviton4 Server CPU – The Next Platform
For more than a year, we have been expecting for Amazon Web Services to launch its Graviton4 processor for its homegrown servers at this year’s re:Invent, and lo and behold, chief executive officer Adam Selipsky rolled out the fourth generation in the Graviton CPU lineup – and the fifth iteration including last year’s overclocked Graviton3E processor aimed at HPC workloads – during his thrombosis-inducing keynote at the conference.
Selipsky did not do the obligatory hold up of the Graviton4 chip during the keynote, which is odd. But the press release did include a chip shot, which is shown in the feature image above.
As we also expected, the Graviton4 is also based on Arm Ltd’s “Demeter” Neoverse V2 core, which is based on the Armv9 architecture as is Nvidia’s “Grace” CG100 CPU. (Officially, Nvidia has not given Grace a product name consistent with its GPU naming scheme, so we are doing it there. The C is for CPU and the G is for Grace.) We did a deep dive on the Demeter V2 core back in September when the “Genesis” Compute Subsystem announcement was made by Arm, and the V2 core has an improvement of 13 percent in instructions per clock compared to the “Zeus” V1 core that preceded it and that was used in the Graviton3 and Graviton3E processors already deployed by AWS.
This is not a big jump in IPC, obviously, and hence the core counts are jumping and that is why we are also assuming that AWS has moved from the 5 nanometer processes from foundry partner Taiwan Semiconductor Manufacturing Co used to etch the Graviton3 and Graviton3E chips to a denser and somewhat mature 4 nanometer process from the world’s favorite foundry. This same 4N process is used to make Nvidia’s Grace CPU as well as its “Hopper” GH100 GPUs – both of which are taking the generative AI world by storm.
The Graviton4 package has 96 of the V2 cores on it, which is a 50 percent boost over the Graviton3 and Graviton3E, and the Graviton4 has twelve DDR5 controllers on it compared to the eight DDR5 memory controllers, and the speed of the DDR5 memory used with the Graviton4 was boosted by 16.7 percent to 5.6 GHz. So the math across all of that, and the Graviton4 has 536.7 GB/sec of memory bandwidth per socket, which is 75 percent higher than the 307.2 GB/sec offered by the prior Graviton3 and Graviton3E processors.
In the presentation by Selipsky as well as in the limited specs that AWS has put out about the Graviton4, the company says that generic Web applications run 30 percent faster on Graviton4 than on Graviton3 (not Graviton3E, which was overclocked and hot), but that databases would run up to 40 percent faster and that large Java applications would run 45 percent faster. Now, that could mean that AWS has implemented simultaneous multithreading (SMT) in the V2 cores, providing two threads per core, like X86 processors from Intel and AMD do and that some Arm chips have done in the past.
We don’t think so, and our comparative salient characteristics table below says there are 96 threads and not 192 threads per socket. We think it is 96 threads per socket and that the doubling of the L2 cache per core to 2 MB has had a dramatic effect on the performance of Java and database applications. You can get 3X the vCPUs by adding two-way SMT, but that would not give you 3X the memory. It would still only be 1.5X the memory compared to a Graviton3 chip.
Something else that AWS said in its blog about the new R8g instances that use the Graviton4 chip also gave us pause: “R8g instances offer larger instance sizes with up to 3X more vCPUs and 3X more memory than current generation R7g instances.”
With 96 cores and a dozen memory controllers – both boosted by 1.5X from the Graviton3 – you would only expect the R8g to have 1.5X as many vCPUs and only 1.5X more memory capacity than the R7g instances using the Graviton3 chip. And so, we think this is the first two-socket implementation of the Graviton family. That is also one reason why we think that the Graviton4 chip has around 95 billion to 100 billion transistors rather than the 82.5 billion you would expect if AWS just added 50 percent more cores to the Graviton3 design and left it at that. The doubling of the L2 cache, the addition of four more DDR5 memory controllers, and a pair of I/O controllers that also now do line-rate encryption also added to the transistor budget, we think.
We think that the Graviton4 is noteworthy in another way. In the past, Neoverse blocks were done in 32 core or 64 core blocks and Arm suggested using chiplets with UCI-Express or CCIX interconnects to build larger processor complexes. Companies making their own Arm CPU designs could always implement a monolithic die, which you would do for latency and power reasons – those interconnects are not free – btu a monolithic die, especially one with 96 cores, would have a disproportionately lower yield than a 32 core or 64 core block. And that has a cost, too.
So we think, looking at the chip shot above, that the Graviton4 is a two-chiplet package, with one chiplet rotated 180 degrees from the other. That is probably why the memory controller chiplets on the left and right of the central core complex on the package are offset from each other.
Here is how we think the Graviton4 stacks up to the prior generations of chips: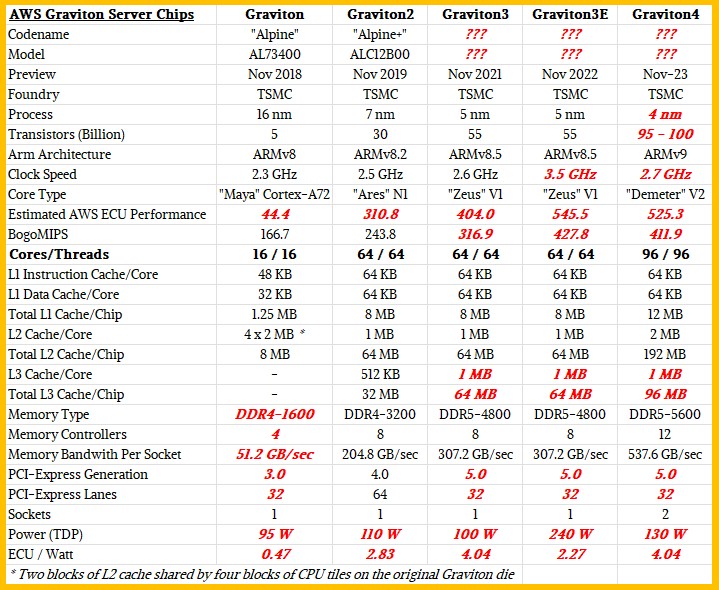
Admittedly guessing, we think that the Graviton4 has a little less performance than the Graviton3E, but burns nearly half the power to get there and has memory capacity that is 50 percent higher and bandwidth that is 75 percent higher within what is probably around a 130 watt power envelope with a much lower – and much more desirable – 2.7 GHz clock speed.
Here is what those chips look like, compliments of Andy Jassy, Amazon chief executive officer, who posted it on Twitter: With these numbers as we have estimated them, shown in bold red italics as usual, the Graviton4 chip has about the same performance per watt as measured in ECU performance units as the Graviton3, which is about all you can hope for with a modest process shrink and a lot more cores.
With these numbers as we have estimated them, shown in bold red italics as usual, the Graviton4 chip has about the same performance per watt as measured in ECU performance units as the Graviton3, which is about all you can hope for with a modest process shrink and a lot more cores.
We will update this story as more details emerge.
One more thing: AWS said in its announcement (but Selipsky did not brag in his keynote) that it has deployed over 2 million of Graviton processors in its fleet to date and has over 50,000 customers that have used them.
That is a very respectable number of CPUs, and if AWS had not started doing Graviton in-house, those chips would have all come instead from Intel, AMD, or maybe even Ampere Computing. But they didn’t. Which is why pinning your business plans to the hyperscalers and cloud builders is a risky proposition.
Featuring highlights, analysis, and stories from the week directly from us to your inbox with nothing in between.
Subscribe now
Companies invest in platforms over a decade or more, and that is why architectures persist longer than we might think given technological differences and economic forces. It is unreasonable to expect a roadmap from any component supplier that spans ten years, but companies do expect to see at least two …
IT organizations are funny creatures, indeed. On the one paw, they are eternally optimistic about the prospects for new technologies, and on the other paw, they are extremely resistant to change because of the economic and technical risks that change requires. For more than a decade now, the people who …
Isn’t it funny how the same hyperscalers who are maniacal about building everything themselves – and who are making a fortune selling access to their infrastructure as cloud services – want you to use their Seriously Hard Information Technology and stop using your own? Don’t you find this just a …
It’s interesting how well Java responds to increased cache size. I guess the runtime environment with JIT compiler has a pretty large cache footprint.
The ending “which is why pinning your business plans to the hyperscalers and cloud builders is a risky proposition” apparently refers to processor manufacturers seeking to sell CPUs to the cloud builder. This warning could apply equally to software developers who optimise their code for a processor design that is only available for rent from a single cloud provider.
“This warning could apply equally to software developers who optimise their code for a processor design that is only available for rent from a single cloud provider.”
This is so true!
I’m not really worried about optimizing my workloads for a specific processor architecture. A lot of software is using Java / Python / PHP / etc and should run unchanged. There are, of course, HPC and other specialized workloads where it takes a lot of work to optimize for vector instructions, etc – but most people in IT aren’t working at this level. The bigger risk may be tying yourself to the services the cloud vendors offer, such as DynamoDB.
Right on!
This is very cool! A64FX’s main challenge (or Fugaku’s) is power consumption (relative to systems with heterogeneous accelerators), leading Fujitsu to focus on its next Monaka chip (10x more power efficient) which unfortunately has looked so far like a kind of N2 or 3 rather than V2 or 3 (exhibited at SC23? https://sc23.supercomputing.org/presentation/?id=exforum111&sess=sess252 ). Having Graviton4 with perf very close to Graviton3E, at essentially half the power consumption, is exactly the way to go in my mind!
You are probably right about 2x 48-core chiplets in there (it makes sense as, for example, A64FX has 48 cores). Interestingly, the total size of vectors in Graviton4 (384x 128-bit) matches that in A64FX (96x 512-bit ~= 384x 128b) and exceeds those of Graviton3E/rhea1 (128x 256-bit) and of one Grace chip (288x 128-bit) (Grace may however be advantageously paired with a Hopper …). This suggests to me the potential for very nice performance (eg. in HPC, maybe esp. in dense 2S configs?)!
Thank you for suffering through deep keynote thrombosis to bring us this great news about ARM’s cheeky twelve Olympians (of the Neoverse)!
I think the transistor count in the article needs to be updated to “billions” from “millions”.
Correct! I can’t read my own chart. . . .
Note AWS states frequency of Graviton 3E as 2.6GHz: https://github.com/aws/aws-graviton-getting-started#:~:text=2500MHz-,2600MHz,-Turbo%20supported
Yup. I think that is the base clock, and they overclock the heck out of it to get the extra performance in the 3E version. There is no other explanation.
There are other possible explanations assuming the CPU and DRAM are identical. Firmware can be tuned for HPC via DRAM and prefetch settings, or simply set a higher max power (Neoverse V1 has 3 power gears: https://www.anandtech.com/show/16640/arm-announces-neoverse-v1-n2-platforms-cpus-cmn700-mesh/3 )
Hello, how do you obtain the TDP data for the various Graviton processors? What are your sources or methods for collecting this data?
Hints and rumor.
Your email address will not be published.
*
*
This site uses Akismet to reduce spam. Learn how your comment data is processed.
The Next Platform is published by Stackhouse Publishing Inc in partnership with the UK’s top technology publication, The Register.
It offers in-depth coverage of high-end computing at large enterprises, supercomputing centers, hyperscale data centers, and public clouds. Read more…
Featuring highlights, analysis, and stories from the week directly from us to your inbox with nothing in between.
Subscribe now
All Content Copyright The Next Platform