AI Neocloud Playbook và giải phẫu
The rise of the AI Neoclouds has captivated the attention of the entire computing industry. Everyone is using them for access to GPU compute, from enterprises to startups. Even Microsoft is spending ~$200 million a month on GPU compute through AI Neoclouds despite having their own datacenter construction and operation teams. Nvidia has heralded the rapid growth of several AI Neoclouds through direct investments, large allocations of their GPUs, and accolades in various speeches and events.
An AI Neocloud is defined as a new breed of cloud compute provider focused on offering GPU compute rental. These pure play GPU clouds offer cutting edge performance and flexibility to their customers, but the economics powering them are still evolving just as the market is learning how their business models work.
In the first half of this deep dive, we will peel back the layers of running a Neocloud, from crafting a cluster Bill of Materials (BoM), to navigating the complexities of deployment, funding, and day-to-day operations. We will provide several key recommendations in terms of BoM and cluster architecture.
In the second half of the report. we explain the AI Neocloud economy and discuss in detail these Neoclouds’ go to market strategies, total cost of ownership (TCO), margins, business case and potential return on investment for a variety of situations.
Lastly, we will address the rapid shifts in H100 GPU rental pricing from a number of different hyperscale and neoclouds, discussing the meaningful declines in on-demand pricing in just the past month, as well as shifts in the term structure for H100 GPU contract pricing and how the market will evolve with upcoming deployments of Blackwell GPUs.
Further granularity and higher frequency data on GPU pricing across many SKUs is available in our AI GPU Rental Price Tracker. Granular data and modeling of future compute capacity, cost of compute and estimations of future GPU rental pricing for multiple current and future GPU SKUs can be found in our AI Cloud TCO model.
-
The Giant and the Emerging
-
Part 1: How to build an AI Neocloud
-
Understanding Cluster Bill of Materials
-
Compute Chassis Bill of Materials
-
Cluster Level – Networking Bill of Materials
-
Optimizing the Back-end Network
-
Optimizing Optical vs Electrical Networking
-
Virtual Modular Switch
-
Oversubscribing Backend Network Optimization
-
AI Neocloud Storage
-
More Network Management and Software Packages
-
Summary of Cluster BoM Capex: Reference Architecture vs SemiAnalysis
-
Optimized Architecture
-
Drivers, User Experience and Software
-
Multitenancy
-
Bare Metal or Virtualization
-
Monitoring and Common Errors
-
More Tips and Tests
-
Cluster Deployment and Acceptance Test
-
Day to Day Operations
-
-
Part 2: The AI Neocloud Economy
-
Demand Ecosystem
-
Decision Chain, Shopping Process
-
Pricing and Contract Types
-
Pricing Trends
-
Cluster Capital Cost of Ownership
-
Cost of Capital
-
Cluster Operating Cost of Ownership
-
Project and Equity Returns, Total Cost of Ownership and Neocloud Business Case
-
Time to Market
-
Future Pricing Thoughts
-
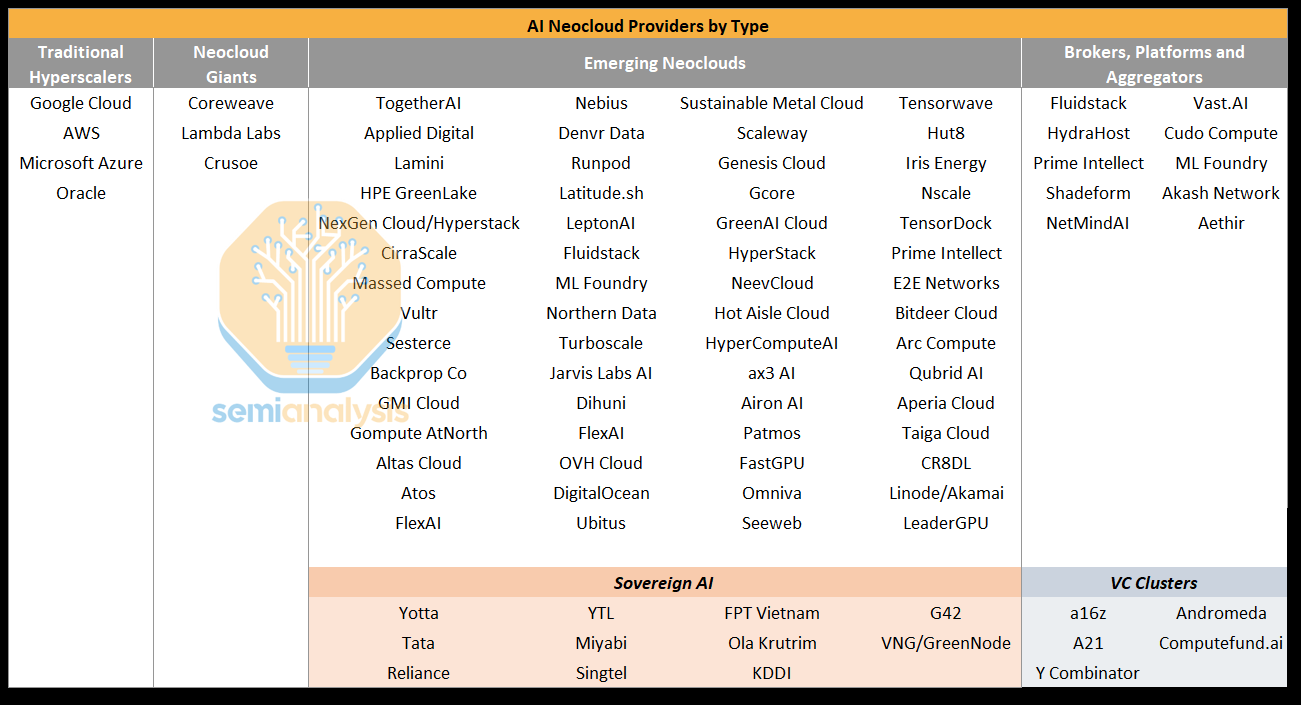
The AI Neocloud market is served by four main categories of providers, Traditional Hyperscalers, Neocloud Giants, Emerging Neoclouds, and Brokers/Platforms/Aggregators.
The AI Neocloud market is huge and is the most meaningful incremental driver of GPU demand. In broad strokes, we see the Neoclouds growing to more than a third of total demand.
Traditional hyperscalers offering AI cloud services include Google Cloud (GCP), Microsoft Azure, Amazon Web Services (AWS), Oracle, Tencent, Baidu, Alibaba. In contrast, Meta, xAI, ByteDance and Tesla, despite also having formidable GPU fleets and considerable capacity expansion plans, do not currently offer AI services, and thus do not fall into this group.
Traditional hyperscalers’ diversified business models allow them the lowest cost of capital, but their integrated ecosystem and data lakes, existing enterprise customer base mean very premium pricing compared to others. Hyperscalers also tend to earn high margins on their cloud business and so pricing is set much higher than reasonable for AI cloud purposes.
AI Neocloud Giants, unlike traditional hyperscalers, focus almost exclusively on GPU Cloud services. The largest have current or planned capacity in the next few years well in excess of 100k H100 equivalents in aggregate across all their sites, with some planning for hundreds of thousands of Blackwell GPUs for OpenAI. The main three Neocloud Giants are Crusoe, Lambda Labs, and Coreweave, which is by far the largest. They have a higher cost of capital compared to the hyperscalers but usually have a better access to capital at a reasonable rate vs Emerging AI Neoclouds, which means a lower comparative cost of ownership for Neocloud Giants.
Emerging AI Neoclouds includes a long tail of a couple dozen clouds that we track that still have small amounts of capacity and are relatively inexperienced at running datacenter infrastructure. These upstarts usually have a higher cost of capital and are the category we will focus most of our time on today. Also included amongst Emerging Neoclouds are many regional players that fall under the Sovereign AI umbrella, which is defined as any AI Neocloud that focuses its business model on the provision of AI Cloud services to a secondary regions outside of the US or China.
These regions are currently far behind in AI technology and include Europe, India, Middle East, Malaysia, etc. In particular their customers generally would like to keep their GPU compute out of the US or China due to regulatory, privacy, data security or other business reason. While most Emerging Neoclouds either have less than 10k GPUs or have yet to deploy GPUs, many of them have extremely ambitious plans that could soon catapult a few of them into the same league as the Neocloud Giants.
Lastly, are the Brokers, Platforms and Aggregators, who generally aggregate demand and supply but tend to be capital light and shy away from taking direct GPU rental price exposure and as such, do not own any GPUs themselves. There are two main business models within this category, Platforms models that provide a Shopify-like platform to help GPU owners and data centers market and matchmake their compute resources on their behalf, and Aggregators that use an Amazon-like Marketplace model for GPU owners that allows them to offer compute to different buyers.
Platforms can provide IaaS infrastructure as well as setup and procurement support for hosts that would like to own GPU compute, but do not have any expertise deploying or marketing clusters. Brokers and Platforms generally require more human touchpoints compared to just an Amazon-like marketplace aggregator are similar to real estate agents that help you find homes for a cut of the transaction value. As with any Brokering or Marketplace service, the broker’s cut of the revenue can be opaque to the end customer.
Another interesting emerging business model that sits outside the above categories are VC Clusters, whereby a Venture Capital (VC) or VC-like entity sets up clusters for the exclusive use of portfolio or other affiliated companies. Notable examples include Andromeda, AI2, Computefund.ai, and Andreesen Horowitz’s planned GPU Cluster. With in-house clusters, these VCs can provide very flexible options for compute rental – offering large 512 or 1k GPU clusters for short periods of times well below what other Neoclouds would charge in exchange for equity. They can also offer generous rental terms to lean further into portfolio or affiliated companies.
Let’s start with a simple framing. So, you want to start an AI Neocloud? What would you do? This is our step-by-step guide, starting with the BoM and concluding with setting up the Neocloud.
Understanding and customizing an AI Cluster quote and Bill of Materials (BoM) is one of the most important factors in a Neocloud deployment, and getting it right can be the difference between strong profit margins or financial distress. We recommend that everyone from the CEO to engineers and sales staff understand every single item line in their BoM.
Most Neocloud Clusters being deployed today have 2048 or fewer GPUs. The most common physical cluster sizes are 2048, 1024, 512, and 256 GPUs, with deployment costs for clusters 2048 GPUs and under scaling linearly with respect to number of GPUs. For this analysis we will focus our analysis on a 1024 GPU deployment as a common denominator for emerging Neoclouds.
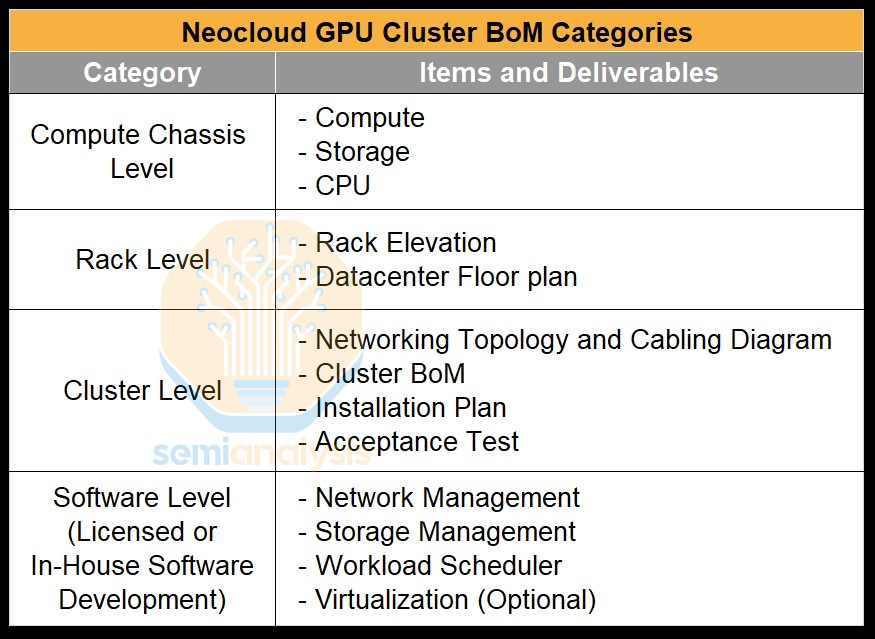
OEMs and Nvidia will naturally seek to upsell when quoting out a BoM. The BoM is usually subdivided up into four categories: compute chassis level, rack level, cluster level and software level.
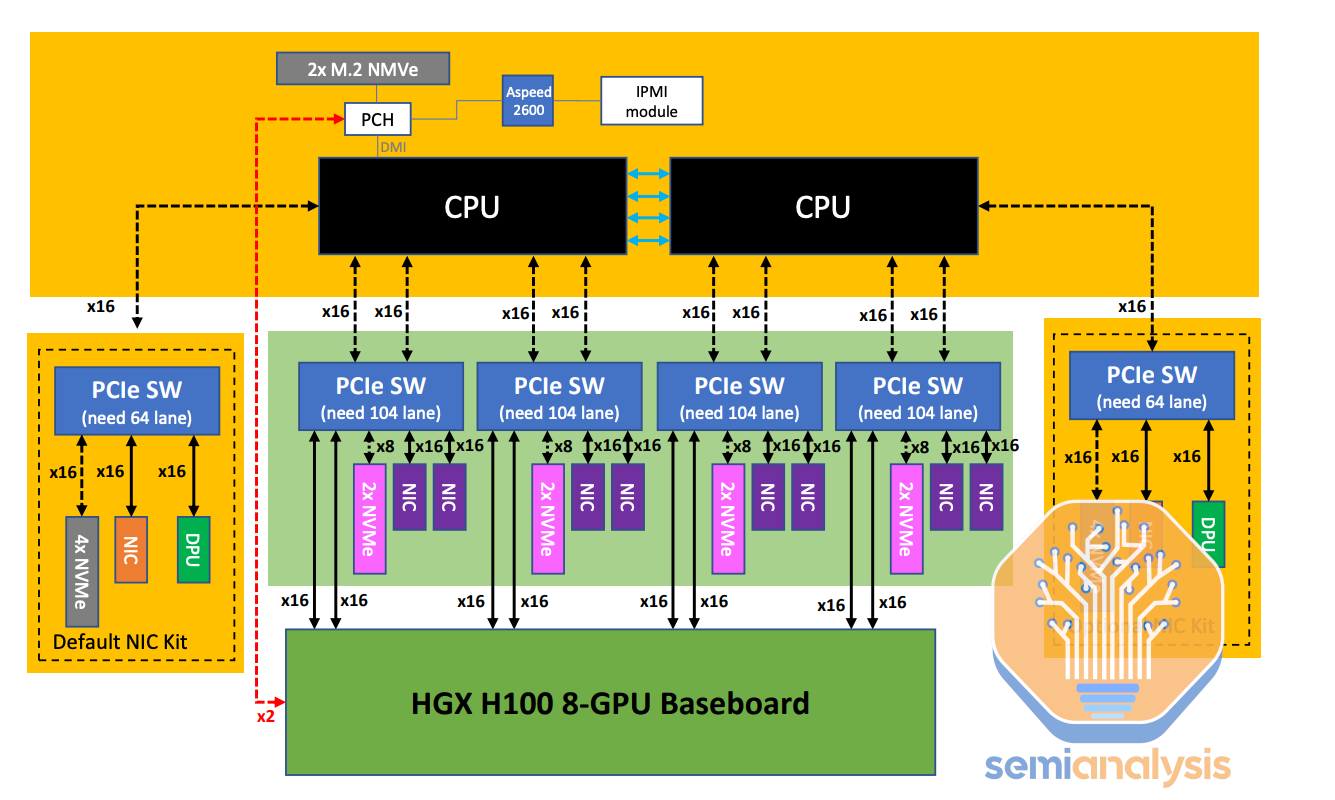
We will start at the lowest level of abstraction, the compute chassis bill of materials (BoM), the most expensive part of cluster. The default compute chassis BoM quote tends to use top of the line components – OEMs such as Supermicro, Dell, etc. will initially quote a near top-of-the-line Intel Emerald Rapids CPU, and a system build that comes with 2TB of RAM and 30 TBytes of local NVMe SSD flash storage.
Fine tuning this quote is the easiest optimization available to an AI Neocloud. The step in this optimization is to choose a mid-level Intel CPU given many customer’s workload will not use the CPU much anyways. LLM training is a very GPU intensive workload but for the CPU, the workload intensity is incredibly light. A CPU will mostly be running simple tasks such as the PyTorch and other processes that are controlling the GPU, initializing network and storage calls, and potentially running a hypervisor.
In general, while AMD CPUs are superior for most CPU only tasks, we recommend using Intel CPUs as on Intel it is easier to get NCCL performance correct, easier to do virtualization, and the experience overall is less buggy.
For example, on AMD CPUs, you need to use NCCL_IB_PCI_RELAXED_ORDERING and play around with different NUMA NPS settings to achieve acceptable performance. If you plan on doing virtualization, you need to correctly pin your virtual cores to the correct NUMA regions or else your Device to Host and Host to Device bandwidth and latency will be not ideal. To be clear, if you are skilled, this is doable.
Many standard offerings have 2TB of CPU DDR5 RAM, but most of your customers will not be using that much. RAM is the 4th most expensive part of the compute chassis BoM. We recommend downgrading from the standard 2 TBytes to only 1TByte of RAM. Most customers of your Neocloud are not likely to ask about RAM capacity as their workloads are not CPU RAM limited at all.
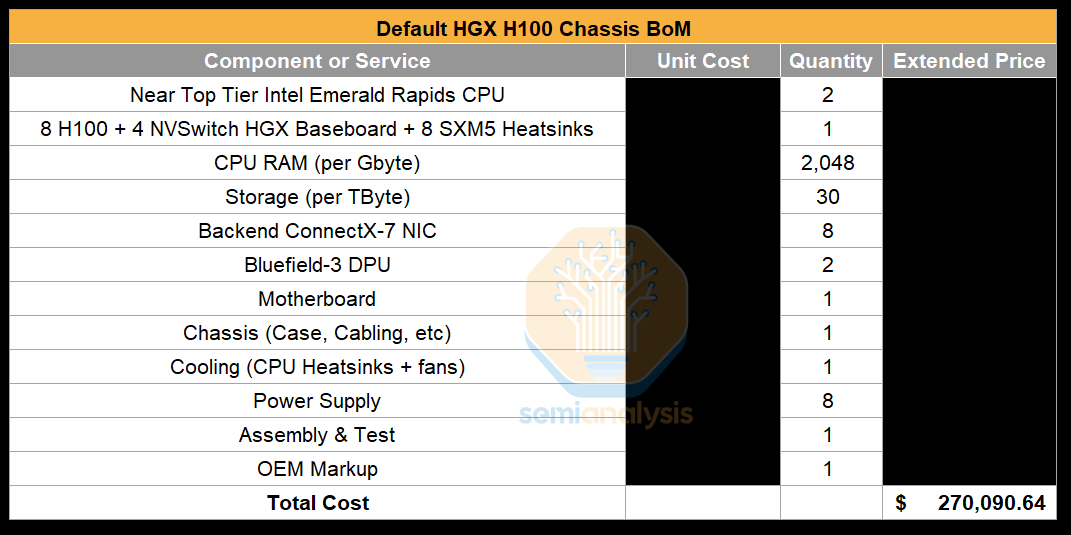

Moving beyond core compute components, another potential cost saving is to remove the two NVIDIA Bluefield-3 DPU present in a standard quote. These DPUs were originally developed and pitched more as a cost savings technique for traditional CPU clouds that would allow them to rent out more CPU cores instead of encumbering those CPU cores with having it run network virtualization.
But your Neocloud customers are not going to be using much CPU compute anyway, so it doesn’t matter if you are using some of the host CPU cores for network virtualization. In many cases you will handing over bare metal servers to your customers anyways, obviating the need for any network virtualization. Moreover, Bluefield-3 DPUs are considerably expensive to the extent that buying another 54-core CPU is cheaper than purchasing a Bluefield-3. Skip the Bluefield-3 altogether and go with standard ConnectX for front end.

Putting these first few cost optimizations together, we estimate that there is a savings of $13.6k, bringing the cost of one compute node (i.e. one server) down from $270k USD to $256.4k USD – roughly a 5% savings. In a 1024 H100 cluster with 128 compute nodes, that is a savings of $1.74M USD. This pricing goes lower lower with solid volume. Contact us with help negotiating as we’ve seen dozens of neocloud and enterprise contracts with OEMs.
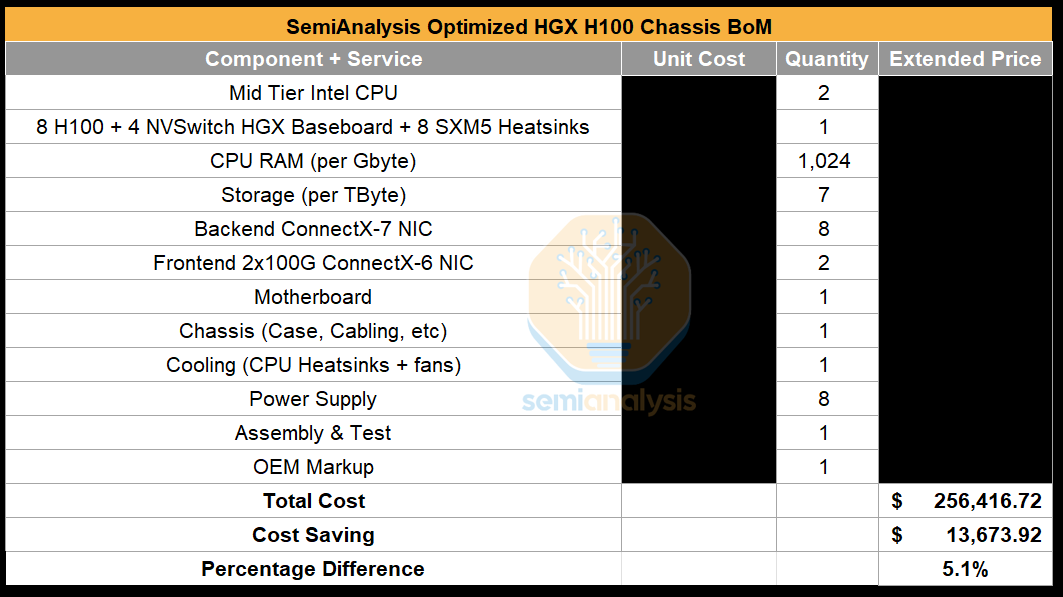
In a typical BoM, each H100 compute server will have eight 400Gbit/s ConnectX-7 NICs leading to a total bandwidth per server of 3,200Gbit/s. Some Neoclouds have only opted for four NICs which would be a 50% reduction in backend networking bandwidth.
While we believe that this might present a better performance per total cost of ownership for certain workloads, most Neoclouds’ target customers are not interested in having anything less than 8x400Gbit/s InfiniBand bandwidth per compute server. Because it does impact workload performance. This is one of the primary reasons why many firms are allergic to Google Cloud. Google Cloud deploys H100s with 8x200G Ethernet using Falcon/GRD. This impacts performance in some cases even if Google does get to save money.

Skipping rack level for now, we will move onto the cluster level BoM, starting with networking, which is the largest cluster cost driver after compute nodes.
There are three different networks in H100 clusters:
-
Frontend Networking (Ethernet)
-
Backend Networking (InfiniBand or RoCEv2 Ethernet)
-
Out of Band Management Networking
As a quick refresher, the frontend networking is simply a normal ethernet network that is used to connect to the internet, SLURM/Kubernetes, and to networked storage for loading training data and model checkpoints. This network typically runs at 25-50Gb/s per GPU, so on an HGX H100 server, this will amount to 200-400Gbit/s per server.
In contrast, the backend compute fabric is used to scale out GPU-GPU communications from tens of racks to thousands of racks. This network could either use Nvidia’s InfiniBand or Nvidia’s Spectrum-X Ethernet or Ethernet from a switch vendor such as Broadcom through a variety of vendors including Artista, Cisco, and various OEM/ODMs. The options from Nvidia are more expensive compared to the Broadcom Ethernet solutions. Despite Ethernet’s perf per TCO, we would still recommend that Neoclouds use InfiniBand or Spectrum X since it has the best performance and will be the easiest to sell as customers associate InfiniBand with the best performance. Customers often assume Ethernet has “way lower performance” even though this does not reflect reality. It mostly stems from the fact there is engineering optimizations that the Neocloud and customer must do to optimize NCCL. We’ve done these before and it isn’t easy unless you have good engineering talent and time. Furthermore many believe Nvidia gives preferred allocations to those buying their networking solutions.
Lastly, there is your out of band management network. This is used for re-imaging your operating system, monitoring node health such as fan speed, temperatures, power draw, etc. The baseboard management controller (BMC) on servers, PDUs, switches, CDUs are usually connected to this network to monitor and control servers and various other IT equipment.
For the frontend network, Nvidia and the OEM/system integrator will usually have 2x200GbE frontend network connectivity on the server, deploying the network using Nvidia Spectrum Ethernet SN4600 switches. However, we would recommend against doing this as having 400Gbit/s per HGX server is way more network bandwidth than what your customer is likely to use. Customers will only be using the frontend network for storage and internet network calls as well as for in-band management for SLURM and Kubernetes. Because the front-end network will not be used for latency sensitive and bandwidth intensive gradient all reduce collective communications, 400Gbit/s per server is going to be overkill. As such, for the overall front-end network deployment we recommend using a generic ethernet switch from vendors like Arista, Cisco, or various OEMs/ODMs instead and only having 2x100GbE per HGX Server.
The next low hanging fruit would be from out of band management networking. The default BoM includes SN2201 Nvidia Spectrum 1GbE switches, but the pricing of these switches is at a considerable premium which is hard to justify for something as simple as out of band networking. This would the equivalent of buying branded Advil instead of the generic Ibuprofen. Using any generic out of band switch will reduce out of band network costs, and as such, we would recommend using a generic 1GbE switch.
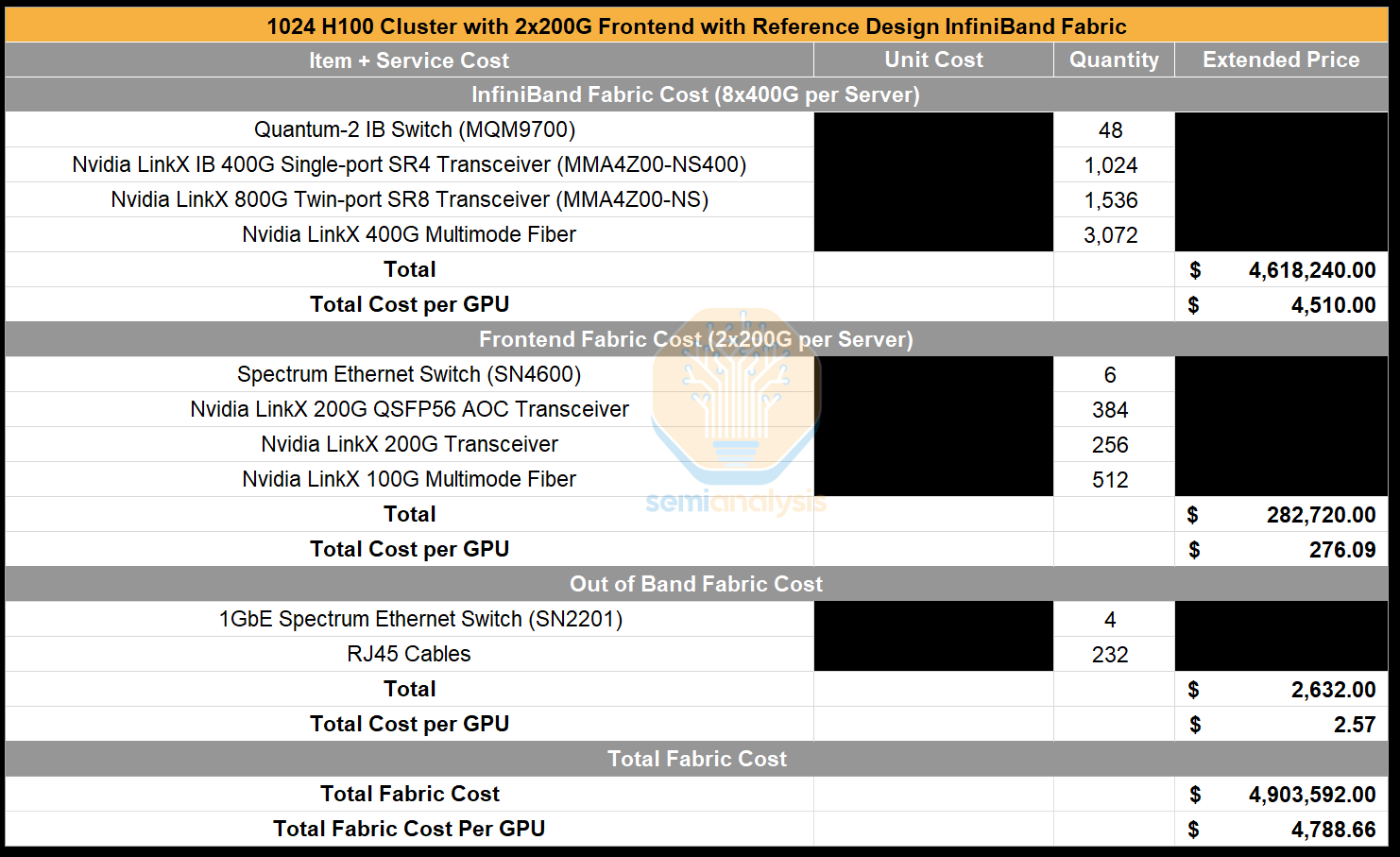
The Backend network is where the choices get more complicated and require a far deeper understanding of high-performance networking, which can at times be lacking amongst newer Emerging Neoclouds firms. This network will run elephant size bursts of All Reduce, All Gather, Reduce Scatter, i.e. your collective communications. Due to the burstiness of these collectives, the back-end network has a completely different traffic pattern compared to traditional cloud networking.
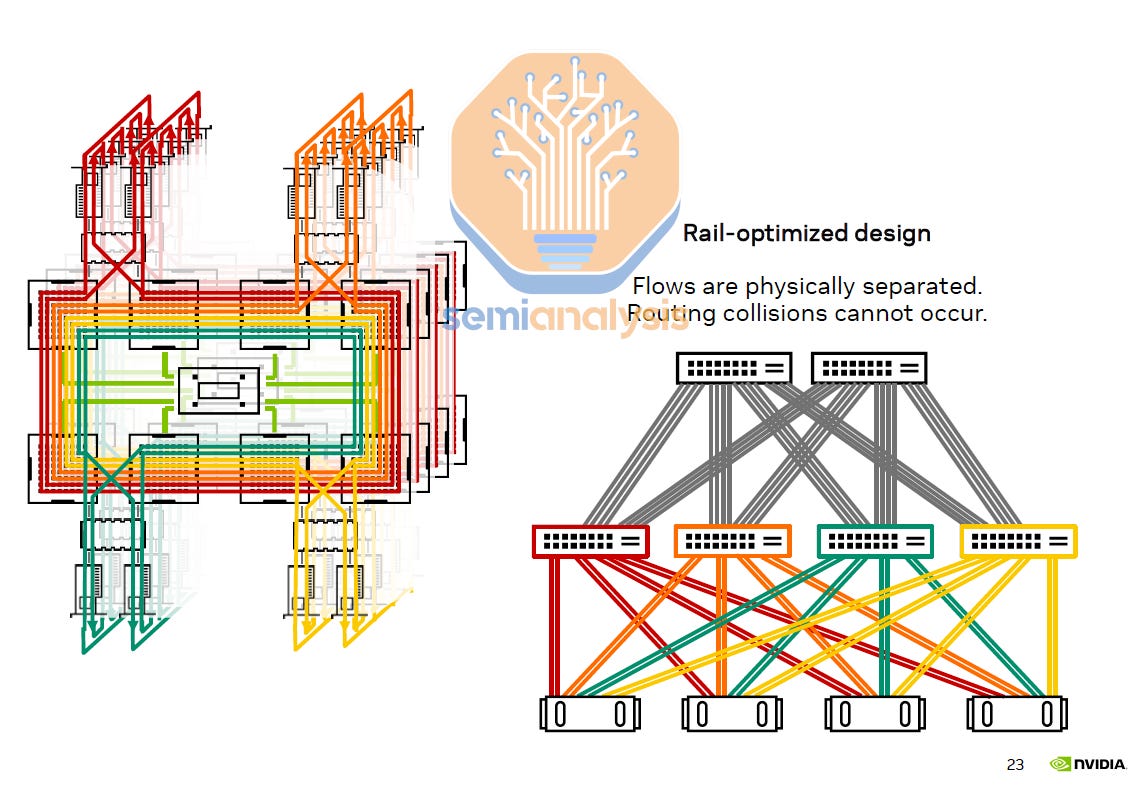
First, we will talk about the Nvidia reference network topology. The reference topology is a two tier 8-rail optimized fat tree with non-blocking connectivity. In a non-blocking fat tree network, if you arbitrarily divide nodes into pairs, then all pairs should be able to communicate to each other at full bandwidth at the same time. Although in practice, this is often not exactly the case due to congestion, imperfect adaptive routing and additional latency of additional switch hops.

When a network is 8-rail optimized, instead of all 32 GPUs from 4 servers connected into a Top of Rack (ToR) switch, each GPU index out of 8 GPU index from 32 servers has their own switch. i.e. all GPU #0 from all 32 servers connect to leaf switch #0, all GPU #1 from all 32 servers connect to leaf switch #1, and so on.
The main benefit of a rail optimized network is to reduce congestion. If all GPUs from the same server were connected to the same ToR switch, when they all try to send traffic into the network at the same time, then the probability that they would attempt to use the same links to traverse the fat tree network would be very high, resulting in congestion. GPUs used for AI training should be expected to routinely send data all at once as collective operations are needed to exchange gradients and update new parameters.
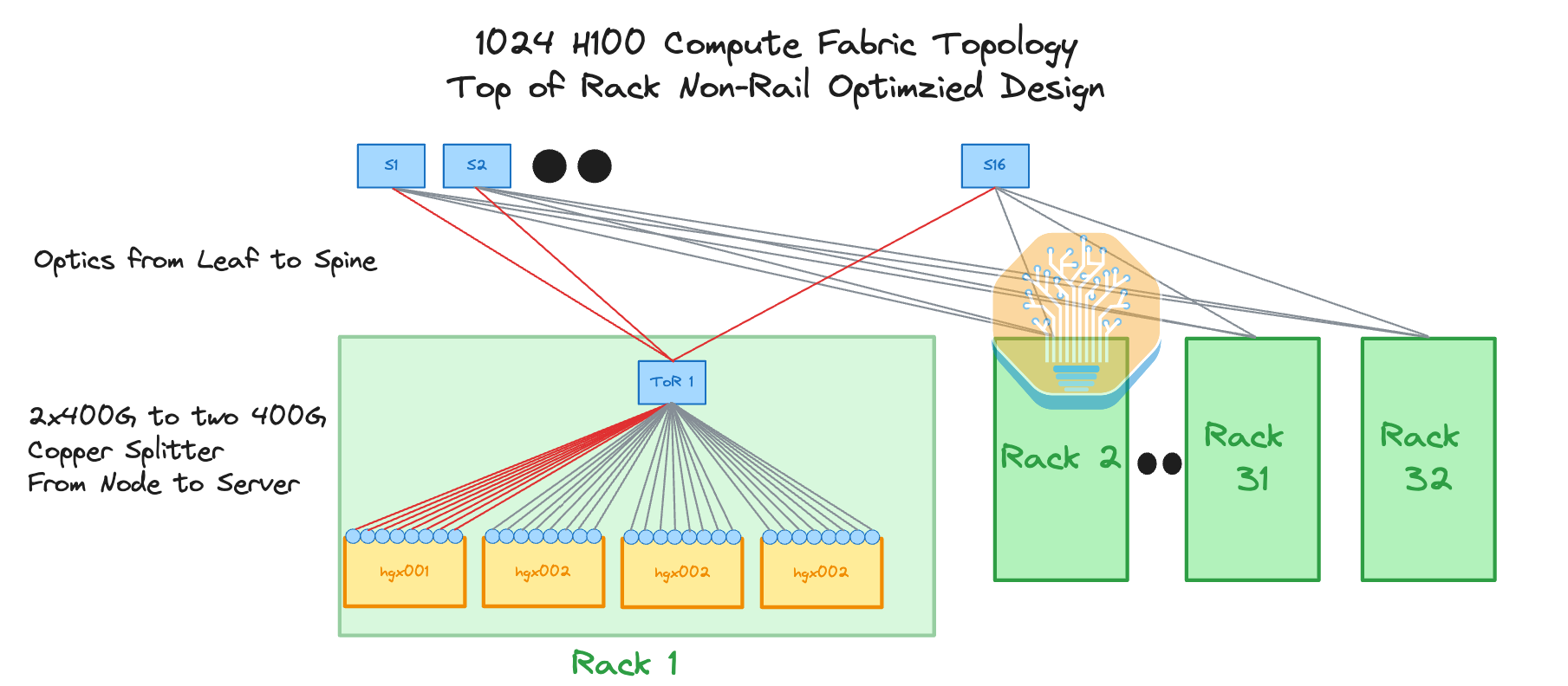
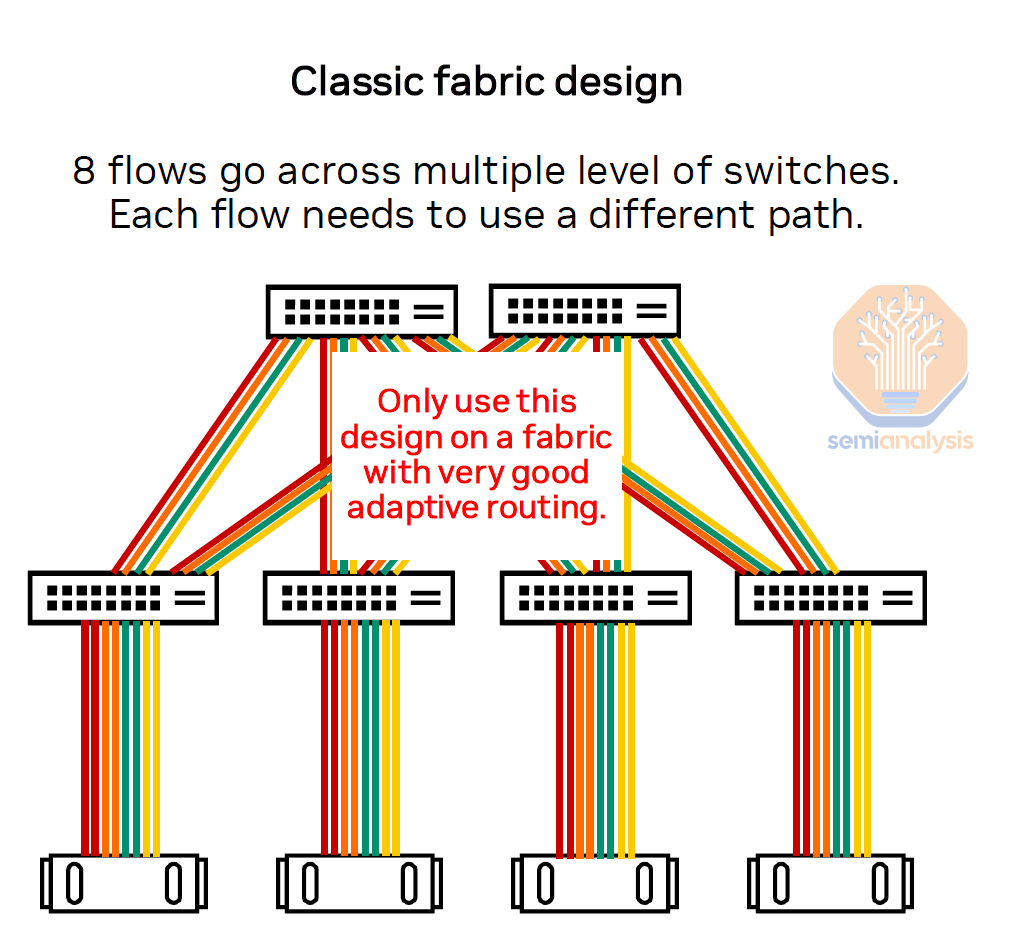
The first diagram below illustrates an 8-rail optimized network in which there are 8 parallel flows from collective communication used to connect to 8 different leaf switches, while the second diagram illustrates a non-rail optimized design with servers connecting to a ToR switch.
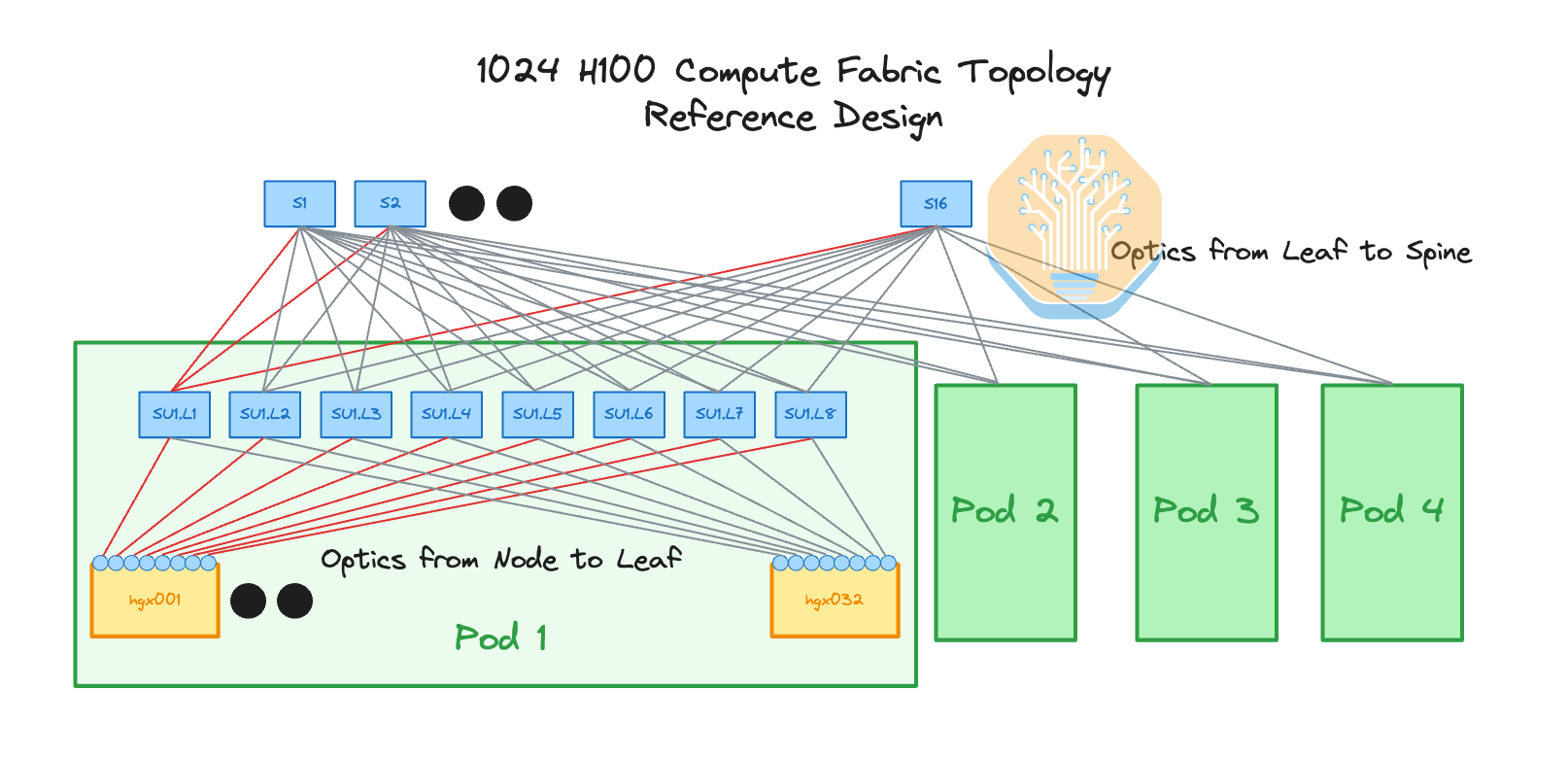
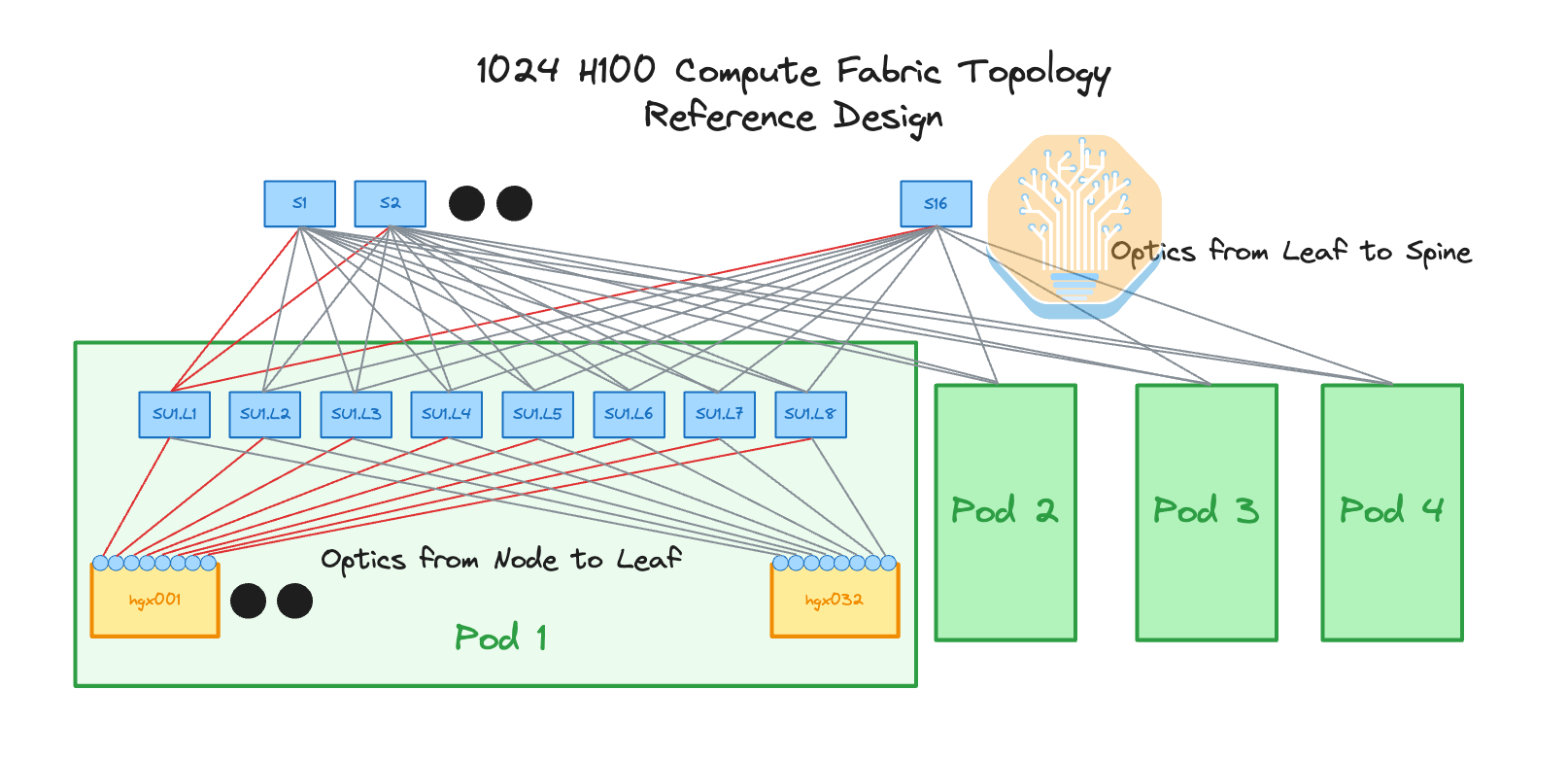
The Nvidia reference architecture also divides the cluster into 4 pods (also known as scalable units or SU), with each pod containing 32 HGX servers (256 H100s) and 8 rails. Each GPU index is always one hop away from the same GPU index in another server within the pod. This is important because it reduces network traffic on the spine switches which can easily be a congestion hotspot (even on non-blocking networks).
Contrary to popular belief, being rail optimized and reducing top level traffic/congestion is especially important in multi-tenant environments such as an GPU Neoclouds where you will very often have multiple tenants/customers. In an 8-rail optimized network, all 8 flows from each workload are physically separated, thus routing/switching collisions cannot occur. In our upcoming Nvidia NCCL and AMD RCCL collective deep dive, we will discuss the benefits of rail optimized configurations and why congestion can be a serious problem, especially for multi-tenant environments such as AI Neoclouds.
Unfortunately, congestion is not something that can be easily measured through nccl-tests and instead requires real world concurrent workloads to see how the noisy neighbor/congestion problems affect end to end workload throughput. Without physical isolation between tenants, noisy neighbors will always exist. Given what we have seen on congestion, we would strongly recommend some form of 8-rail optimized topology.
One other benefit of a rail optimized topology is that since most of the traffic will be local to the leaf switches, it is possible to oversubscribe the spine layer of your network, an architectural optimization that we will discuss later on in this article.
The use of optics for networking has the advantage of much longer reach, but the drawback is in its added power requirements and very high cost of optical transceivers, particularly when purchasing through Nvidia directly, which is basically a must for InfiniBand networking. Optimizing the physical network topology and rack layout can allow you to reduce the use of optical transceivers, saving them only for when the longer reach is actually required.
In the Nvidia Reference Design, the leaf switches are on a separate networking rack and the spine switches are on a dedicated networking rack meaning that using 100% optics is required.
One network topology that can be considered to this end is a non-blocking Top of Rack (ToR) design. Most people coming from a traditional networking background will instantly recognize this design as it is the most common design in traditional networking where there is a switch in the middle or at the top of the rack that connects to all the servers in the rack. Since distances from the ToR switch to the server are less than 3 meters, we can use “cheap” passive copper cables called Direct Attach Copper (DAC) cables to connect from the server to the leaf switch. For this design, we recommend placing the InfiniBand switch in the middle to shorten the distance that the DAC cables need to travel.
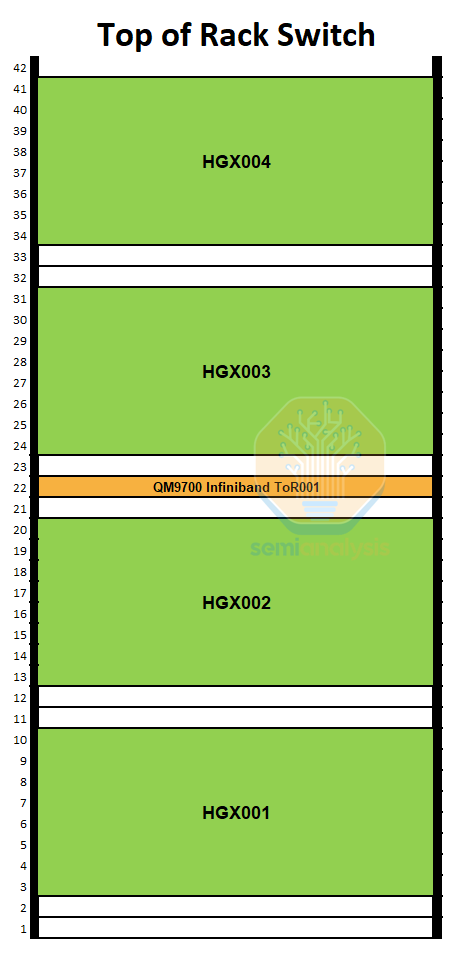
From the leaf switch to the top tier spine switches we will have to use optics. This is expensive, but at least 50% of your connections will now be replaced with cheaper DAC copper cables.
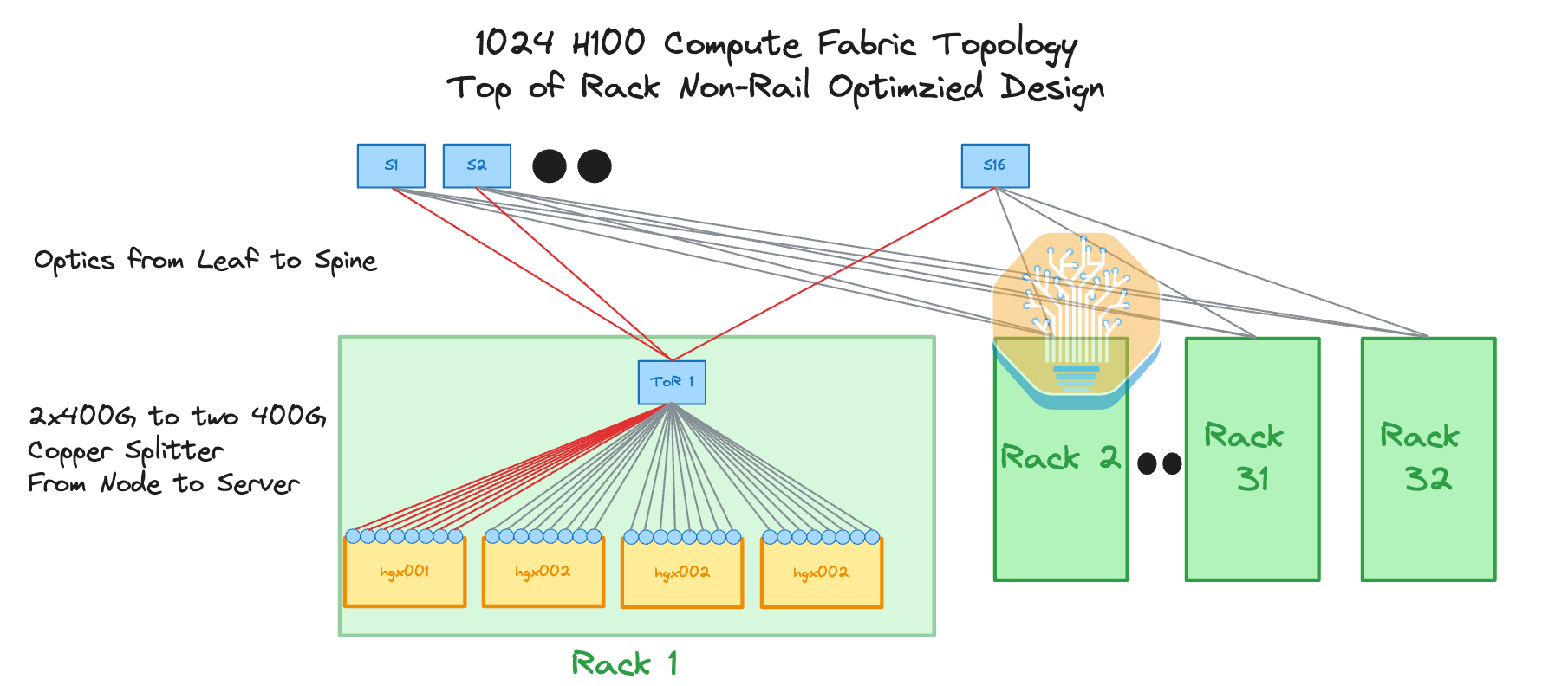
Unfortunately for this design, you will not be able to implement 8-rail optimized networking, and as such you will commonly run into congestion hotspots at your spine layer even if it is non-blocking as there are now 8 flows going across multiple levels of switches, meaning that each flow will need to dynamically use different paths to avoid congestion. In a perfect world where you have perfect adaptive routing, ToR will work well as a topology since the routing will always avoid a congested route. But in reality, because perfect adaptive routing does not exist, and implementing this topology will hurt network performance a lot.
In the diagram below is our simulated heatmap of this non-blocking top of rack fabric where the lighter blue color indicates less bandwidth due to congestion and dark blue means near full line rate. As you can see, using a ToR topology, it is possible to reach line rate but there is still considerable congestion due to all 8 flows going into one switch, with throughput becoming far more jittery and less bandwidth with these flows due to congestion.
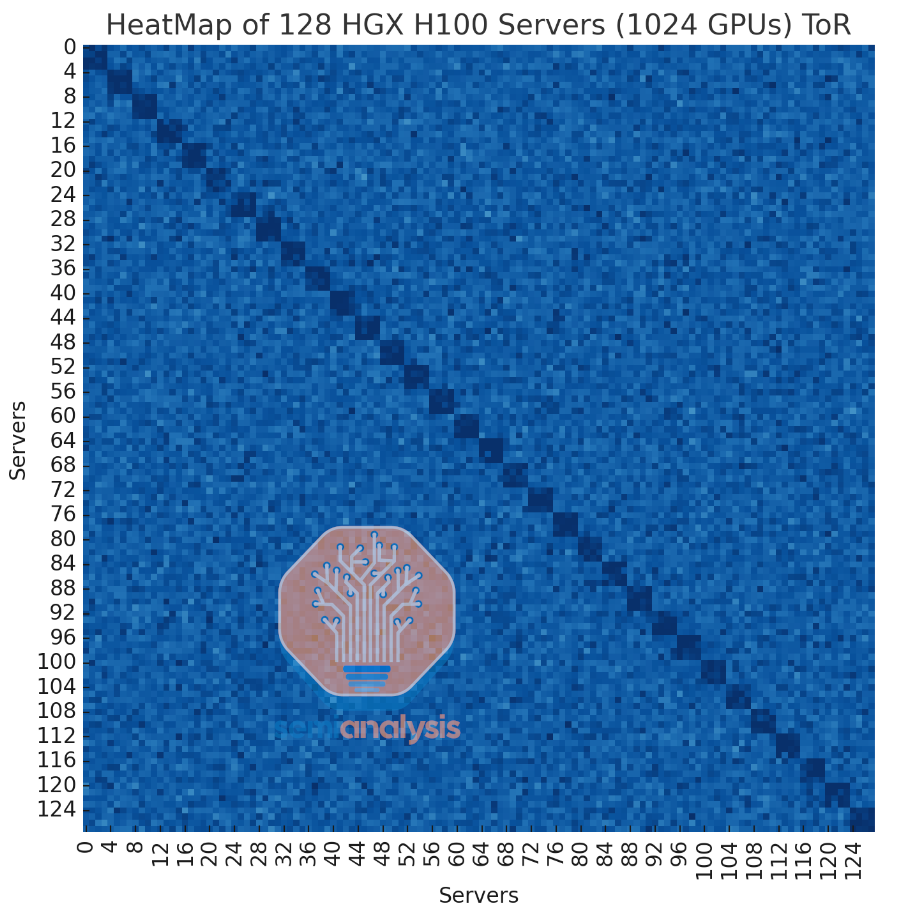
Even though the performance of this design is not particularly good for multi-tenant environments like Neoclouds, the cost savings are huge, saving 34.8% of the backend InfiniBand fabric cost.

Now, what if we could have the best of both worlds – the performance benefit of 8-rail optimized while also having the cost saving of ToR?
This is where a virtual modular switch comes in. It has the same logical topology as the Nvidia reference design but can use copper from the leaf switches to the spine switches due to clever floor planning and switch location planning.
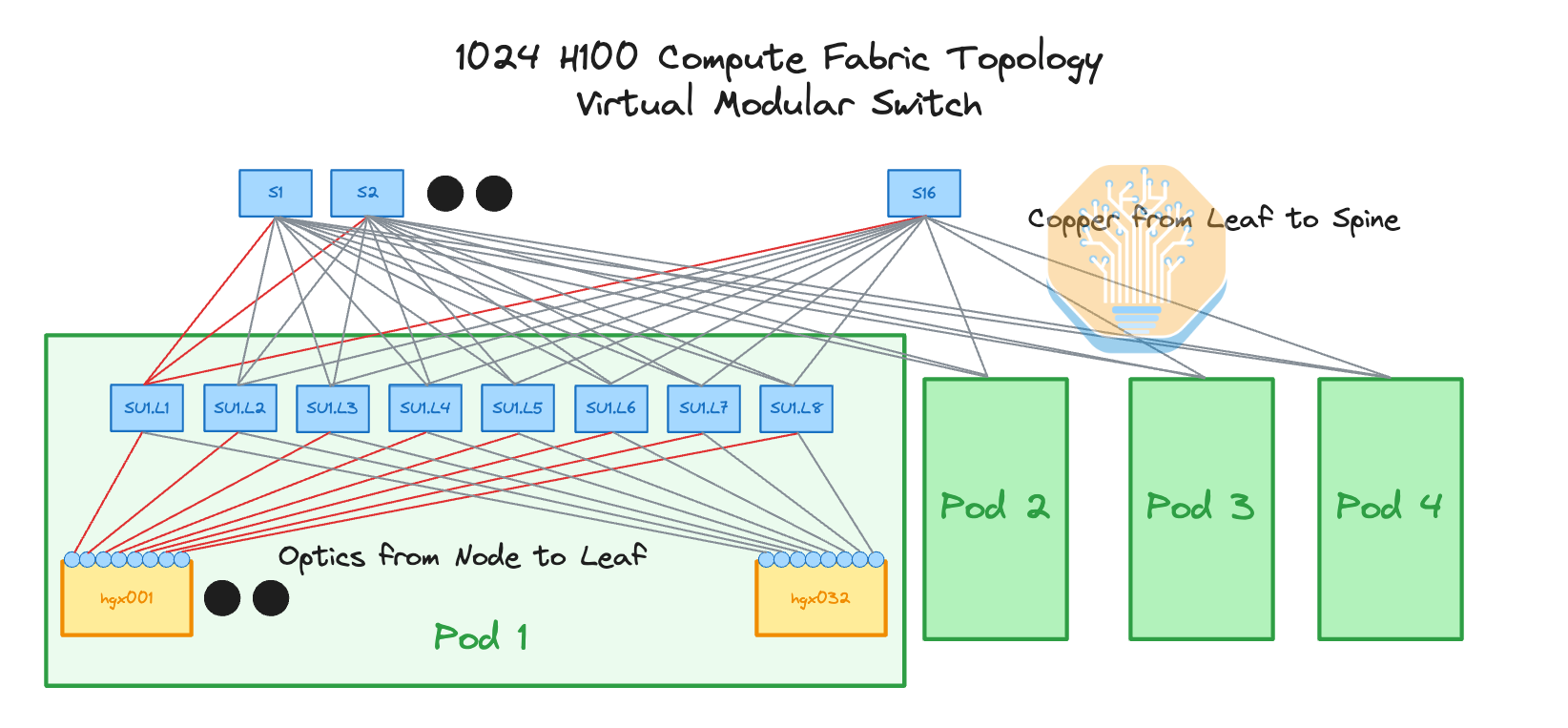
The basic idea here is to place the switch racks directly between each other such that the spine switches are in the middle rack while the leaf switches are the left and right rack as illustrated in the diagram below. This way, the connections between the leaf and the spine switches can be all copper while the connections between the servers and the leaf switches will still use optics.
Since the topology is still 8-rail optimized, each one of the 8 flows will be physically separated, significantly reducing congestion.
This design should give us the best of both worlds, but what are the drawbacks of this topology?
Unfortunately, these switch-to-switch DAC copper cables often tend to have a poor bend radius and are very thick, leading to blocking of air flow. We have seen designs like this being deployed in production before, and if you cable manage it well, these issues can be overcome. This problem can also be tackled using active copper cables (ACC), which are almost as thin as multimode fiber and have a good blend radius. Unfortunately, one potential issue that we heard about is that the error rate on Nvidia’s LinkX NDR ACC cables is not very good.
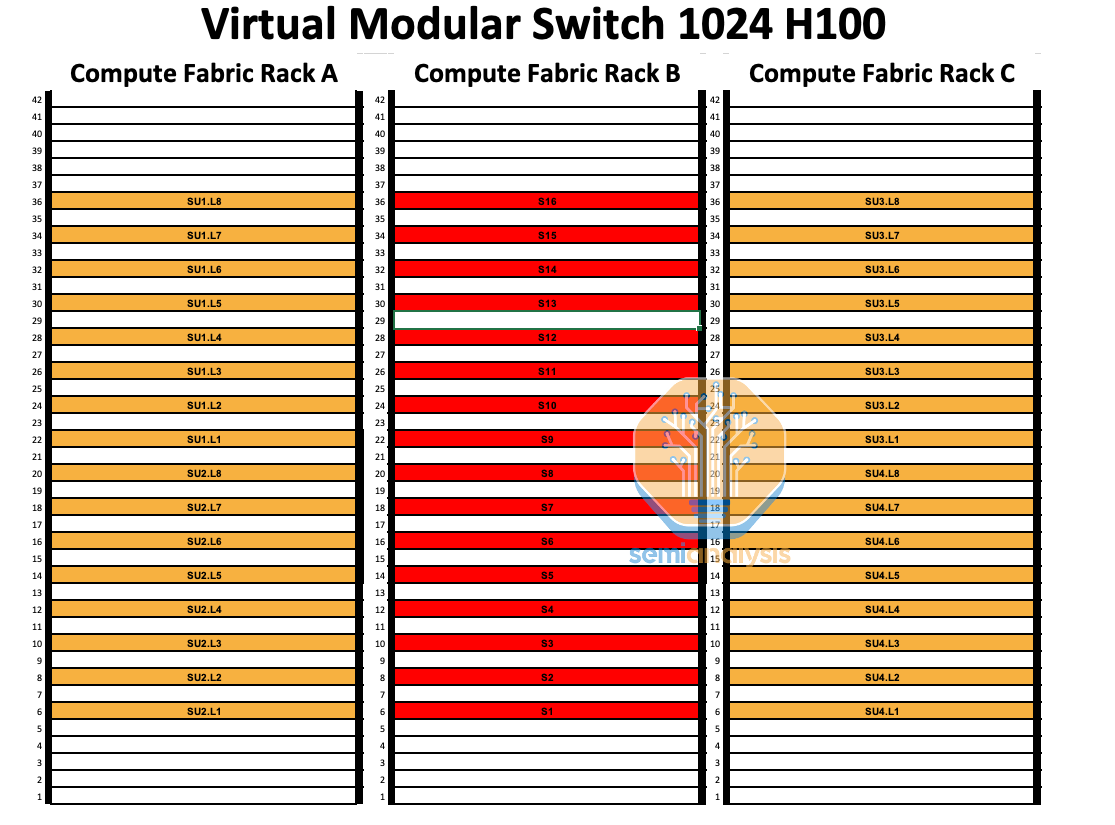
Using this non-blocking virtual modular switch design, we can save 24.9% on the Backend network compared to the reference architecture while maintaining the same performance. One other huge benefit is that passive copper is generally way more reliable than optical transceivers. Transceiver failure rate is high with the lasers being the primary component of failure. This high failure rate introduces costs in terms of the replacement transceiver parts, cluster downtime and labor needed for repairs.

We can take cost optimizations a step further by stepping out of our constraint of having a non-blocking network. Since most of the traffic is local to the pod of 32 servers in an 8-rail optimized design, and because InfiniBand has decent enough adaptive routing, you can design in an oversubscription from the leaf switches to the spine. This has benefits even if the cluster will be used by single tenant running only one workload. When using 1024 GPUs, you will never have a single model replica be larger than 256 GPUs. That means that tensor, expert and pipeline parallelisms, which tend to be more bandwidth intensive, will run inside a pod of 32 servers.
That traffic will stay local to the first level of switches, while your less bandwidth intensive data parallelism, gradient, and all reductions will happen across the spine switches. Since bandwidth requirements at the spine layer is on the lower end of the spectrum and there is decent enough adaptive routing with InfiniBand, you can have subscription through design alone.
On Meta’s 24k H100 cluster, they implemented a 7:1 oversubscription between pods, but we believe that designing in a more conservative oversubscription makes more sense, and we recommend using just a 2:1 oversubscription for small clusters.
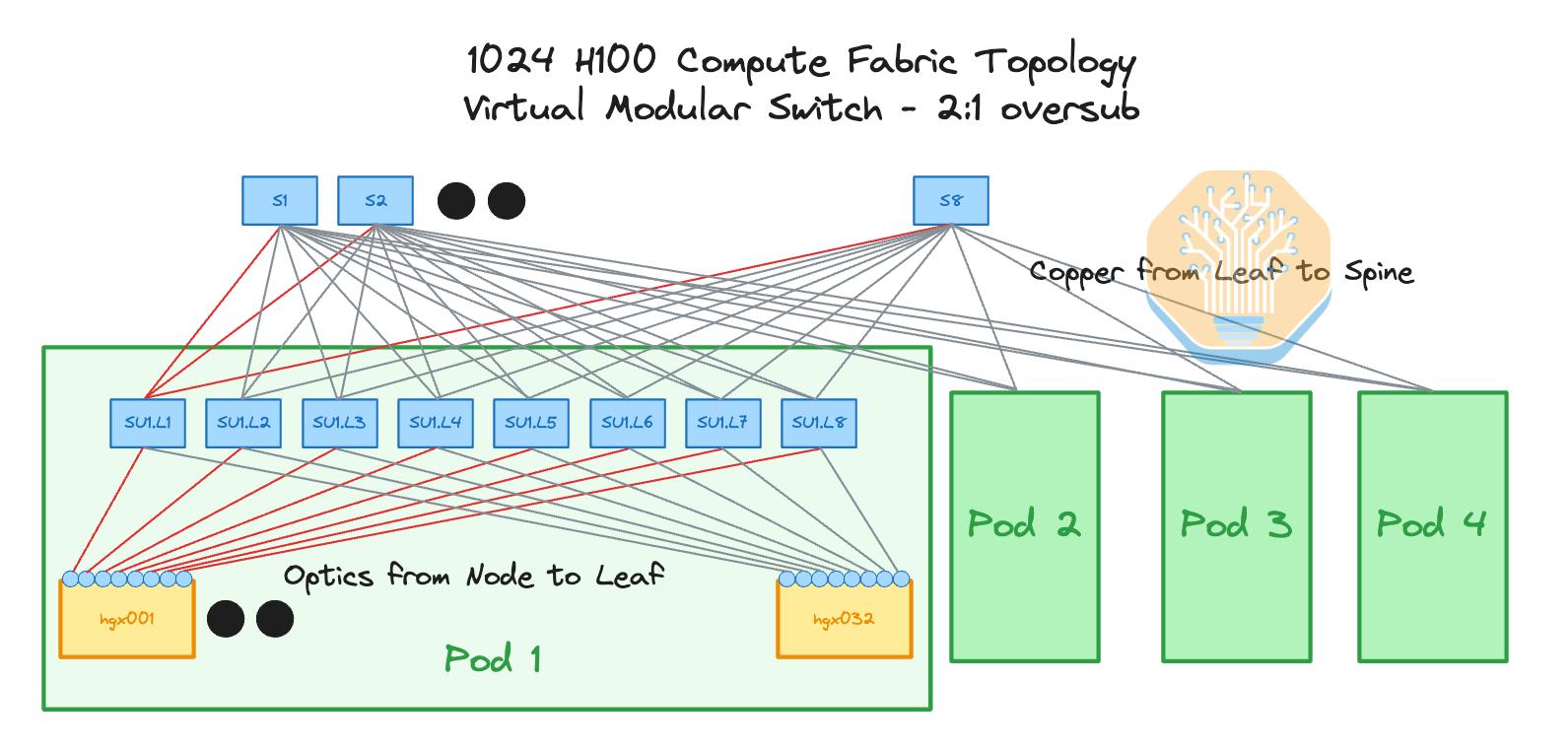
The benefit of this design is that instead of requiring 16 spine switches for 1024 H100s, you only need 8 spine switches. When combining a 2:1 oversubscription with the Virtual Modular Switch design, we can have fewer switches in the middle rack. This means cable management is much easier. Another benefit is empty ports on your leaf switches so in the future, when you have heavier inter-pod traffic, you can easily add more spine switches and reduce the degree of oversubscription.
We estimate that the cost saving for 2:1 oversubscription with the virtual modular switch will be 31.6% compared to the reference architecture, an improvement over the 24.9% savings when only using the non-blocking virtual modular switch design. The only drawback of a non-blocking design (other than the higher cost) is that you need to allocate your customers to physical servers decently well and avoid fragmentation between pod boundaries. We believe that with a competent team, this can be easily achieved.

Nvidia also offers their own physical modular switch for NDR InfiniBand through the CS9500 series. You can use this switch to create the same 8-rail optimized fat tree topology and also do an oversubscription if preferred. This modular switch can support up to 2048 400Gbit/s external ports and thus is expandable to connect up to 2048 H100s. The spine switch ASICs are on the backside of the rack while the leaf switch ASICs and OSFP cages are on the front side of the rack. The spine switch ASICs are connected to the leaf switch ASICs through a copper backplane similar to the NVL72 backplane. Unfortunately, only a liquid cooling solution is offered.
The CS9500’s liquid cooling requirement is why we recommend just deploying a virtual modular switch instead of a physical modular switch for most Neoclouds. The current GB200 driven demand for liquid cooling-ready colocation, and the crunch of colocation supply in general means there will not be much reasonably priced capacity for emerging Neoclouds. Since Nvidia prices based on value to the end user, and as this physical modular switch may be very valuable to large cluster deployments (think O(10k) to O(100k)), we believe that this costs more than just making your own virtual modular switch.

Unfortunately, one of the downsides of using InfiniBand is that to have a decent REST interface, you need to buy UFM management licenses. Unified Fabric Manager (UFM) is a software package offered by Nvidia that handles network management, performance optimization and monitoring. Using UFM is recommended for clusters below 2048 GPUs and is a hard requirement for a cluster of larger size. UFM licenses are charged on a per NIC endpoint basis, meaning that for a 1024 GPU cluster, you will need to buy 1024 licenses.
An alternative to purchasing UFM would be to use the open subnet manager which is only available through a terminal command line interface, but fortunately you can create a simple REST server that wraps the command line and uses a subprocess python library to execute the commands for you. For your first cluster, we would recommend just buying a UFM license but for future clusters, this is something we recommend Neoclouds look into for cost savings.
We will talk about the next most expensive part of an H100 cluster, networked NVMe storage. This is something that all customers want and is practically a requirement for running SLURM. There are basically only two line items for a storage deployment, your physical storage servers and your storage software vendor licenses such as with Weka or Vast Data, etc. These are the most popular vendors due to their channel partnerships with OEMs.
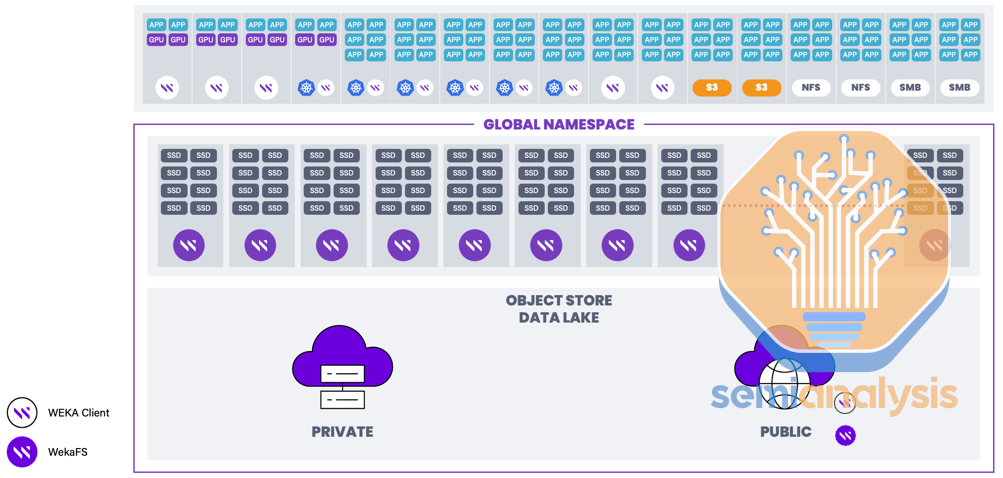
For high availability, most storage software vendors recommend you deploy at least 8 storage servers. Indeed, most Neoclouds only deploy the bare minimum of 8 storage servers. With 8 storage servers, you will get between 250GByte/s to 400GByte/s of aggregated storage bandwidth at big block sizes across all storage servers. That’s more than enough to cater to most reasonable or unreasonable AI workloads one could possibly run on 1024 H100s.

Because lead times for storage are very short, we recommend you start off with 2 PetaBytes of total storage capacity for a 1024 H100 cluster as you can easily expand storage if you see your customers are utilizing your deployed capacity. Our recommendation is to leave enough ports, NVMe drive bays, power and rack space within your storage deployment to allow for easy expansion. Most of the storage cost is in the storage software license and not the physical storage servers itself.

Although your storage servers could run on InfiniBand backend compute fabric, those who have tried have lost a lot of hair! This deployment will typically bind your IB NIC for GPU 0 to also act as your storage NIC. In hero storage benchmarking, this will deliver great latency and high bandwidth, but in real world workloads, this will cause your GPU 0 to be a straggler as utilizing the IB NIC for storage will create collisions. When disks fail in your storage cluster, a rebuild will be triggered, which will cause a meaningful amount of network traffic on your compute fabric, causing even more congestion. You could buy a separate dedicated storage fabric but this is overkill since you can just have storage traffic on your frontend networking.
Our recommendation is that you put your storage servers and traffic on the frontend network. The frontend network often sits underutilized as it is used primarily for internet traffic, SLURM/Kubernetes management and pulling container images.
In terms of in-band management to run high availability UFM and CPU management nodes, we recommend deploying at least three CPU nodes. Out of these three nodes, two will require a ConnectX NIC to manage the InfiniBand fabric. The third CPU node will only be used for other non-InfiniBand management tasks. Furthermore, there are other miscellaneous IT equipment required such as physical firewalls, 42U Racks, monitored PDUs, among other items, but the price point for these items doesn’t add significantly to total cluster capex cost.
In the default Superpod Reference Architecture, Nvidia and their OEM partners will try to sell you something called “Nvidia AI Enterprise” or “Base Command Manager (BCM)”, for which the MSRP is at $4,500 per GPU per year. BCM is a software package that provides AI Workflow & Cluster management, but as most clients will cater to their own workflow needs, this is not a valuable piece of software to a Neocloud business, but sales reps will nonetheless market this as part of their initial purchase order. This is another source of huge cost savings in our SemiAnalysis Optimized Cluster BoM.
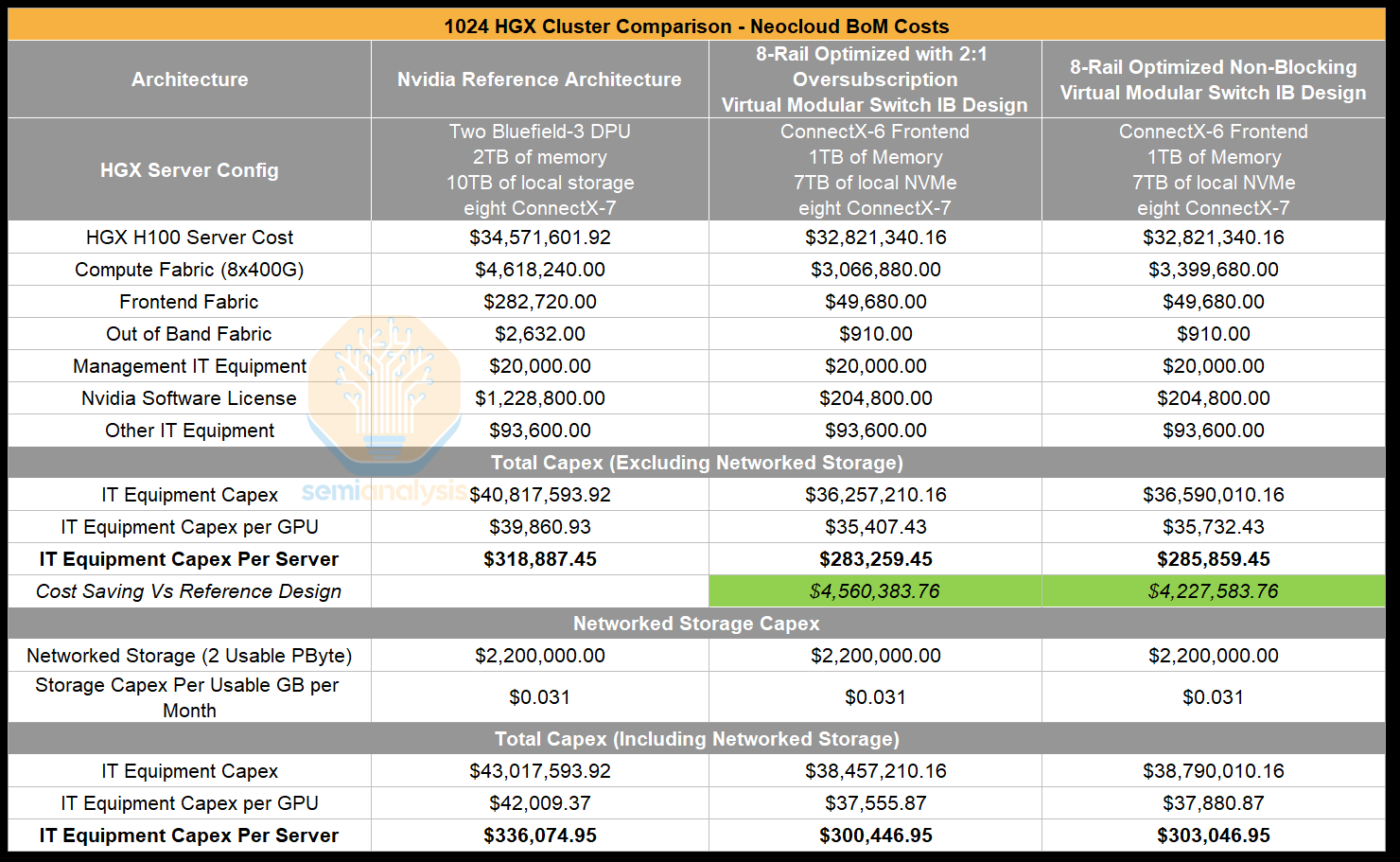
As you can see below, with the Nvidia Superpod Reference Architecture (RA), the all-in cost for the cluster comes up to ~$318k per compute server (excluding storage), but using the SemiAnalysis Optimized Architecture with a 2:1 oversubscription, total all-in cost will just be $283k per compute server (also excluding storage). We have helped Neoclouds optimize further beyond shown through negotiation help, and further cost cutting especially on larger clusters.
If you come from big tech or from a national HPC lab, user requirements are straightforward. Users want functioning GPUs, networking, properly installed drivers, a functioning shared storage and a scheduler such as SLURM or Kubernetes. However, the reality is that a vast majority of Neoclouds are not able to meet these user requirements which makes for poor user experiences.
Starting with GPU drivers required to run the GPUs – we need cuda-drivers-5xx and fabricmanager-5xx, and cuda-toolkit-12-x.
Cuda-drivers-5xx is the kernel space Nvidia drivers needed for ubuntu/Linux to interface with the GPUs. Next is fabricmanager-5xx, a software package responsible for configuring the intra-node NV link fabric. Without the fabricmanager-5xx package, the 8 GPUs within a node would not able to communicate with one another over NV link. Cuda-toolkit-12-x which is the toolkit that contains all the userspace tools and APIs like NVCC which is the compiler that compiles CUDA C++ code into PTX assembly and Nvidia machine code.
For the networking, Mellanox OpenFabrics Enterprise Distribution (MLNX_OFED) drivers are required to be installed on each GPU server. This package are the drivers for the ConnectX-7 InfiniBand NICs to do RDMA-ing (Remote Direct Memory Access-ing) and OS kernel bypassing. For your GPUs to talk directly to your NIC, you also need GPUDirect RDMA, an additional kernel driver that is included in cuda-drivers-5xx but not enabled by default. Without this driver, the GPUs will need to buffer messages in CPU RAM before these messages can go to the NIC. The command to enable GPUDirect RDMA is “sudo modprobe nvidia-peermem”. To further optimize your GPU to NIC communication, you need to download a package called Nvidia HPC-X.
Without the aforementioned GPUDirect RDMA and HPC-X packages, your GPUs will only be able to send and receive traffic at 80Gbit/s out of the line rate of 400Gbit/s per GPU. With these packages enabled, your point to point send and receive rate should reach 391Gbit/s out of the line rate of 400Gbit/s.
Next, users will want a scheduling and launching software package. In the Neocloud market, 70% of users want SLURM working out of the box, another 20% want Kubernetes working out of the box and the last 10% mostly want to install their own scheduler.
It is quite important for Neoclouds to have SLURM or Kubernetes working out of the box as the end user is usually not experienced in installing these types of schedulers. This is because users who come from big tech, or a national/university lab background, which usually have a dedicated person in charge of installing and operating these SLURM software. The cost for an end user having to spend 1-2 days to install SLURM themselves is significant as they will effectively be paying for a GPU cluster that is sitting idle during the installation time.
Finally, 100% of customers also must be able to manually get an interactive terminal (i.e. ssh) into their GPU nodes if needed – having managed SLURM provides this feature. With SLURM, you can run “srun –gres=gpu=8 -w NODE_NAME –pty bash” to get an interactive terminal into any node.
Neoclouds like Crusoe and TogetherAI are the gold standard. Because they have all the required InfiniBand drivers, GPU drivers, and scheduling software installed out of the box, they can charge a premium over their competitors and have lower churn.

The next user requirement for a minimum valuable experience is having a snappy shared home directory and shared data storage directory. All GPU nodes and login nodes will have shared storage mounted at /home/$USER/ and at /data. What this really means is that when the end user can launch an interactive terminal into any GPU node, the node will have the same home directory and files. This is fantastic as it means that every GPU Node allocated to the user is fungible and the user need not care about exactly which GPU server they are using. Furthermore, when launching multi-node training jobs, all of the user’s code is automatically on every GPU node so the user doesn’t need to manually copy code over ssh (scp) to each node.
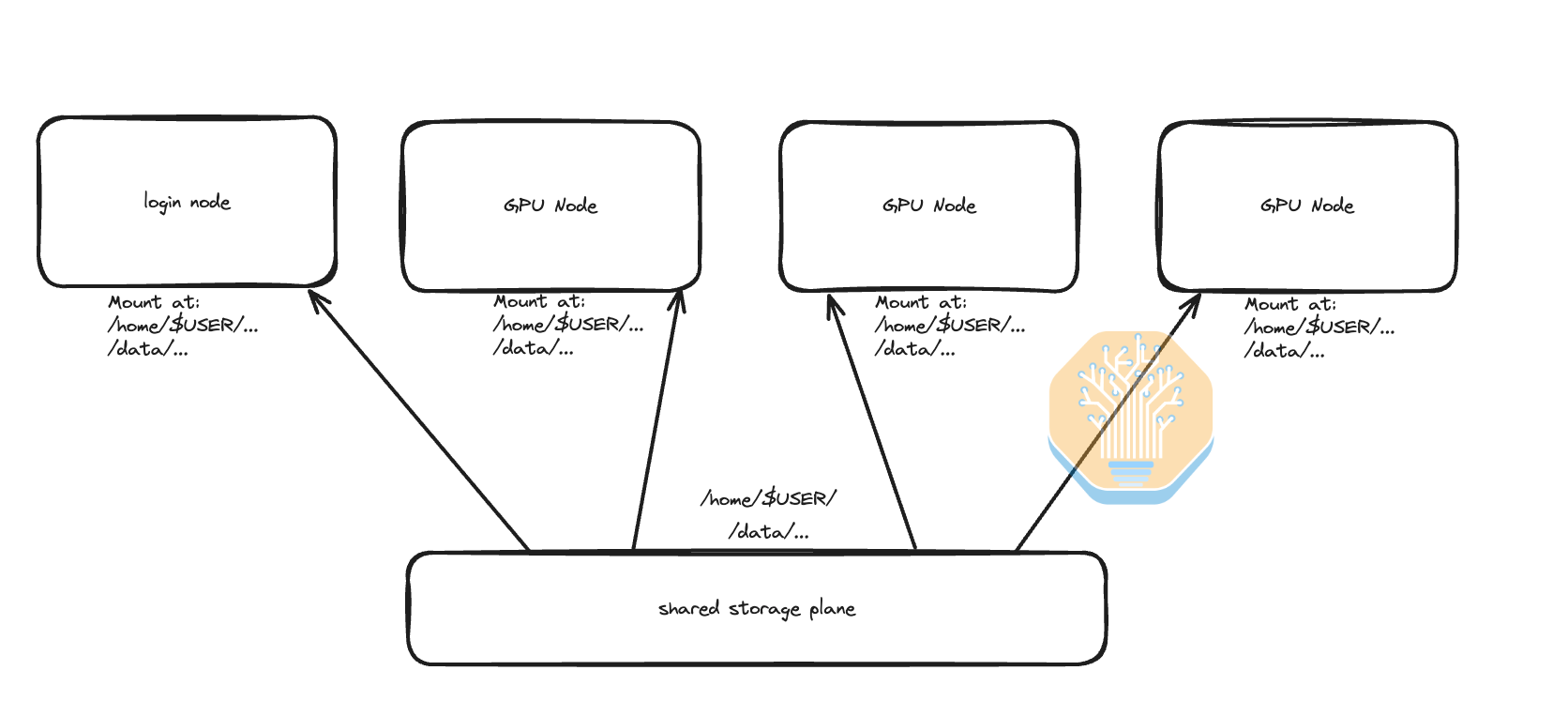
With Neocloud storage, the main two sources of user frustration of storage are when file volumes randomly unmount and when users encounter the lots of small file (LOSF) problem. The solution to the random unmounting issue is to use a program called “autofs” that will automatically keep your shared filesystem mounted.
Next, the LOSF problem can easily be avoided as it is only an issue if you decide to roll your own storage solution like an NFS-server instead of paying for a storage software vendor like Weka or Vast. An end user will very quickly notice an LOSF problem on the cluster as the time to even import PyTorch into Python will lead to a complete lag out if an LOSF problem exists on the cluster.
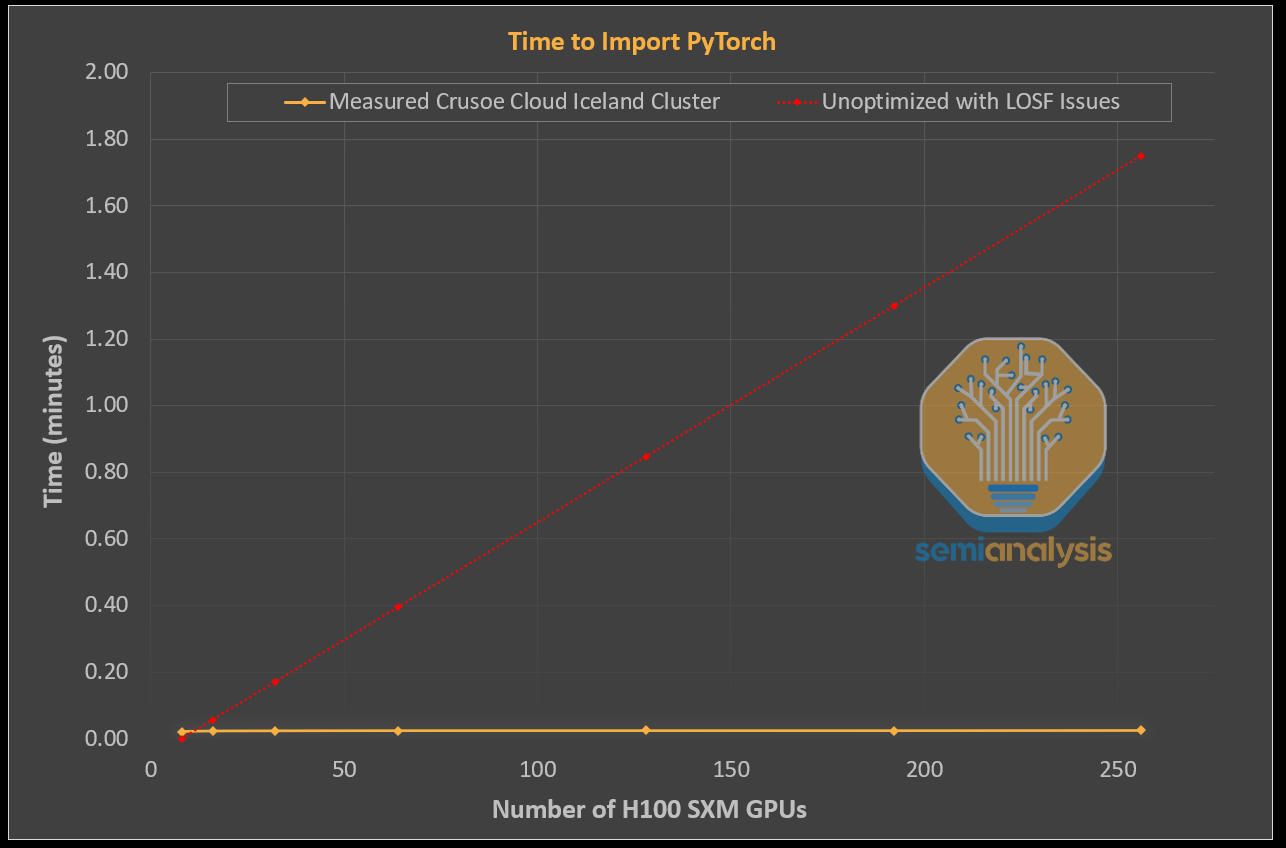
The below diagram, produced during our testing on Crusoe’s cluster, demonstrates how a cluster storage solution that is optimized and free of the LOSF problem should behave. As you can see, the time to complete importing PyTorch into the python process stays relatively flat even when scaling up GPU count.
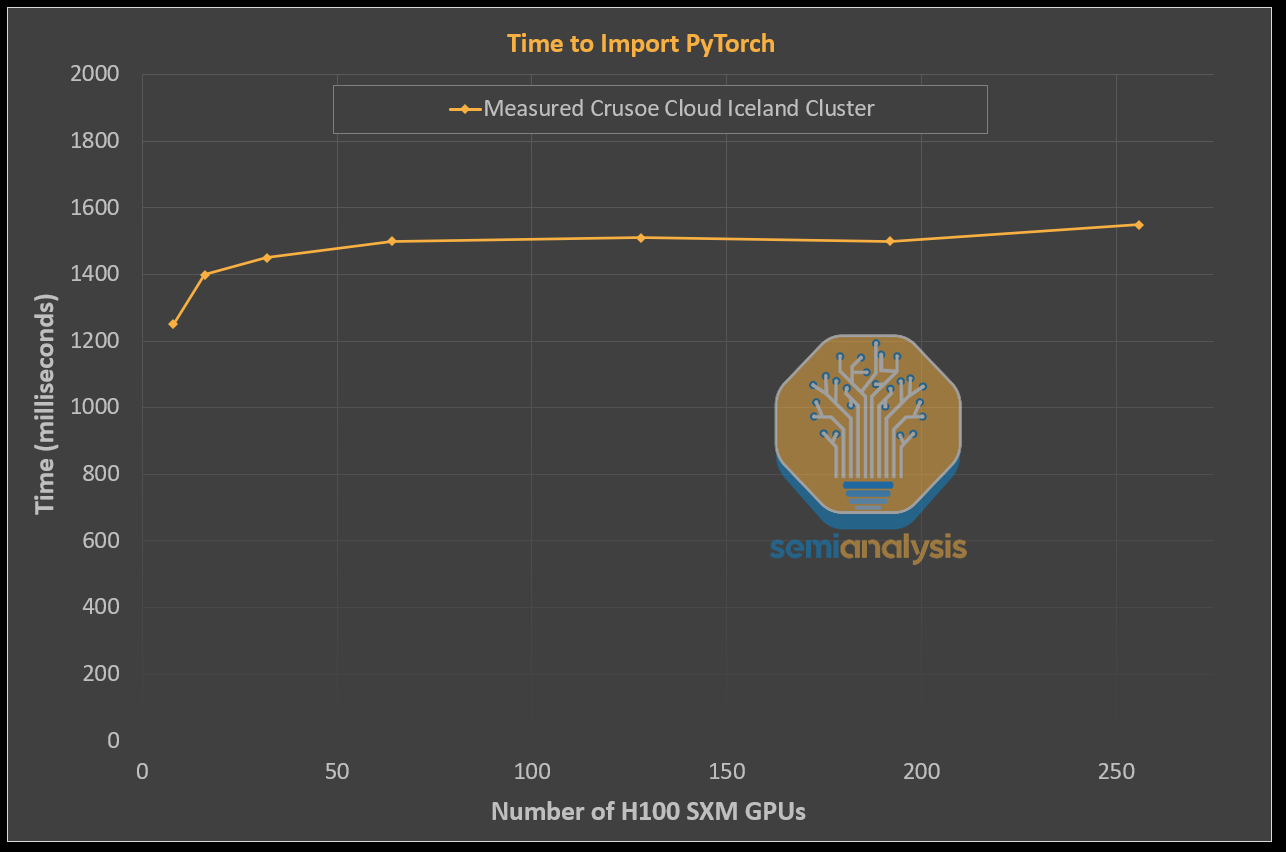
This is a world of difference to a cluster that is running on unoptimized shared storage, where the time required to import PyTorch in a Python multi node training run explodes, often causing the cluster to be completely unusable. Notice the difference between Crusoe, the gold standard, and how another cluster with LOSF issues would behave.
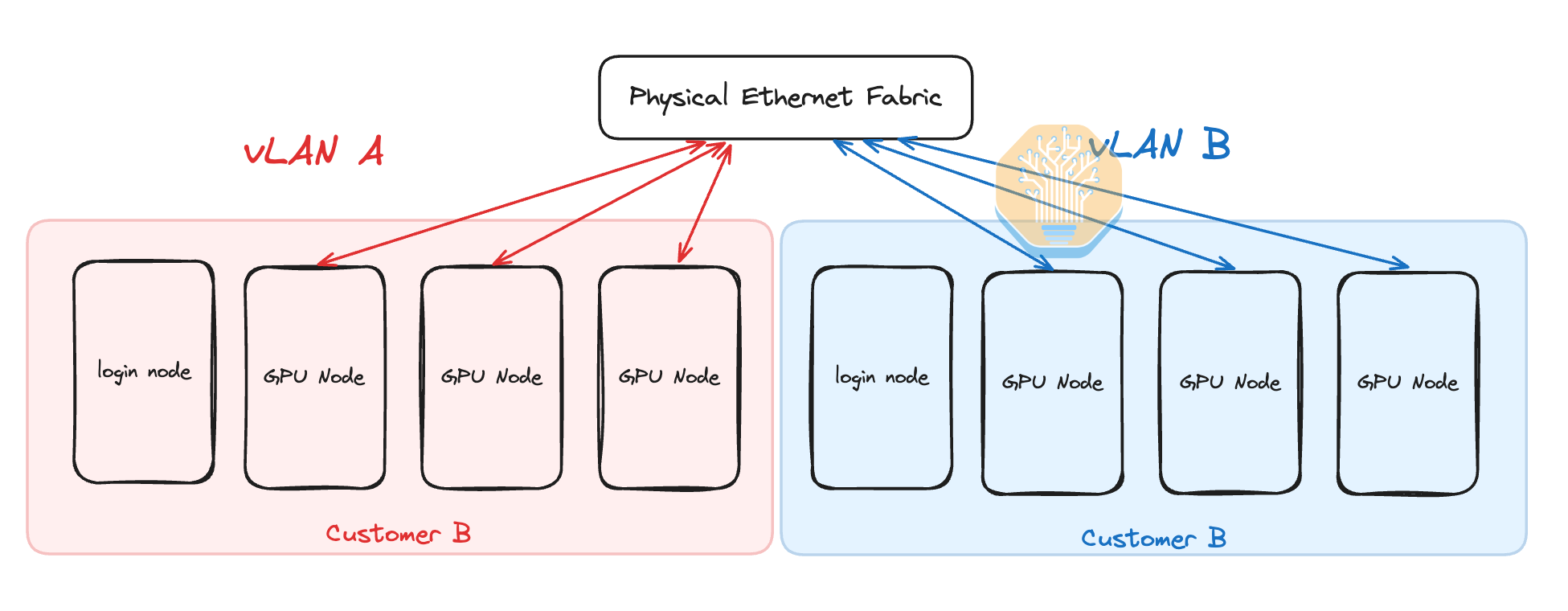
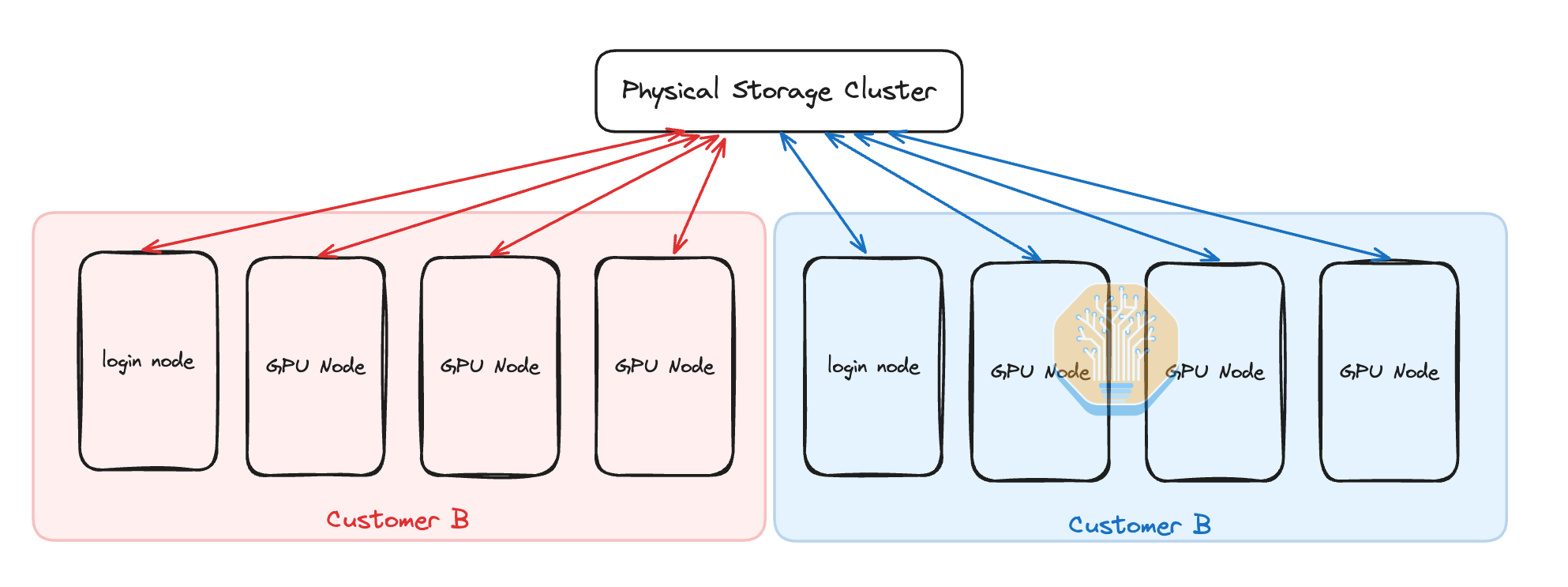
Unless an entire customer (tenant) rents the whole physical cluster out for a long term, each physical cluster will probably have multiple concurrent customers. This means that you need to provide isolation of the frontend Ethernet and backend InfiniBand networks as well as implement isolation of storage between customers. Each customer will typically be renting each GPU server as a whole unit, that means on compute server virtualization is not strictly needed as there is only one customer per physical server. Spending time on subdividing nodes is not worth it. Isolation is easy to set up for the frontend ethernet network using the standard vLANs. In vLAN, while the physical ethernet fabric is shared, each customer’s nodes are only able to talk to other nodes that are assigned to the same customer.
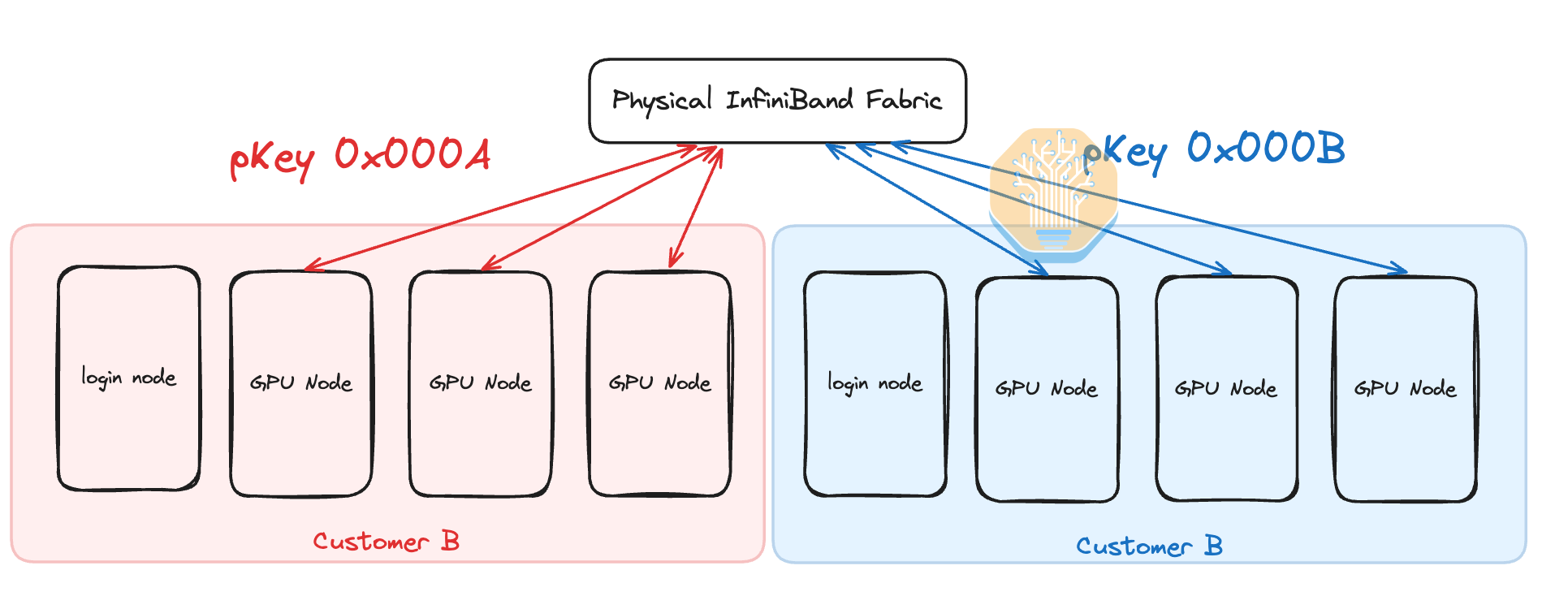
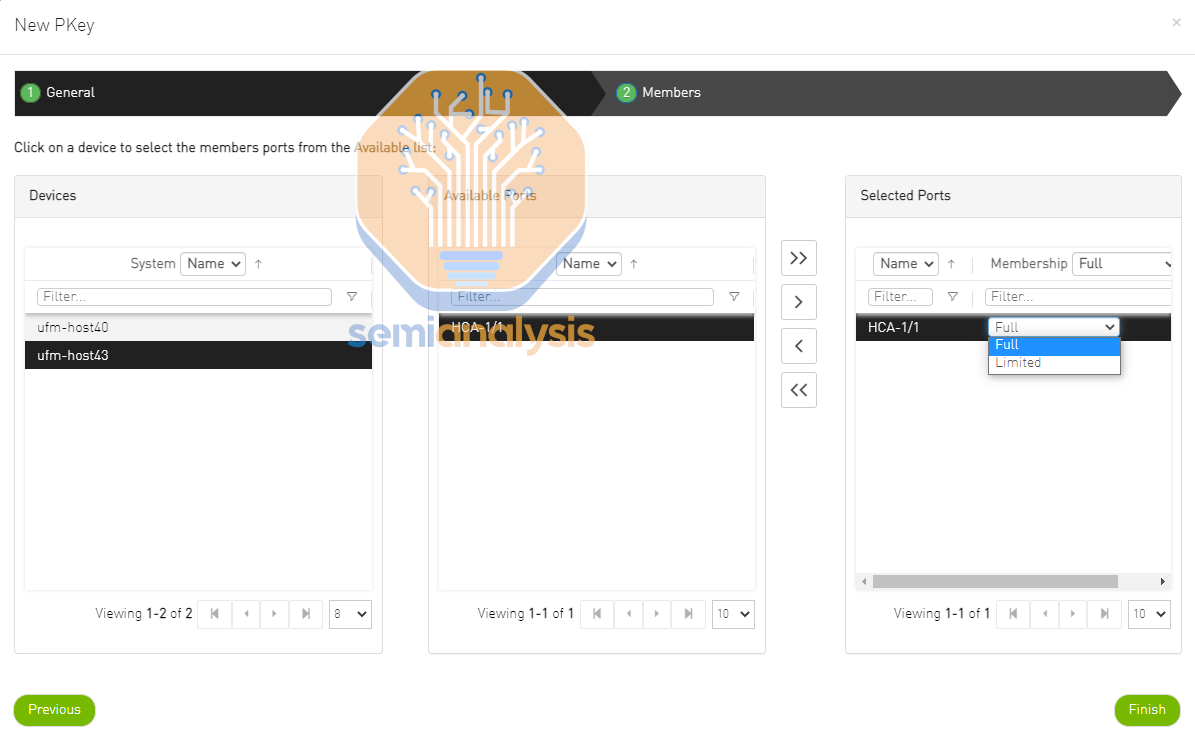
InfiniBand multi- tenancy is not as easy to set up and automate when compared to Ethernet vLAN, but the learning curve is very quick. In the InfiniBand universe, network isolation is accomplished using Partition Keys (pKeys) – essentially the same concept as vLAN. Each customer gets its own isolated InfiniBand network through pKeys and only nodes with the same pKeys can talk to each other.
The creation and attachment of pKeys can either be easily done through the UFM UI dashboard or through using the UFM REST APIs. For many engineers, this may in fact be easier than automating Ethernet vLAN since there is an easy to use POST/GET/DELETE API for InfiniBand pKeys.
Unfortunately, we have seen from our own experience testing that some Neoclouds have pkeys that are not properly set up, allowing one customers’ users to be able to see their other tenants’ nodes on the InfiniBand network. We highly recommend that customers personally verify that their InfiniBand network is properly isolated from other customers.

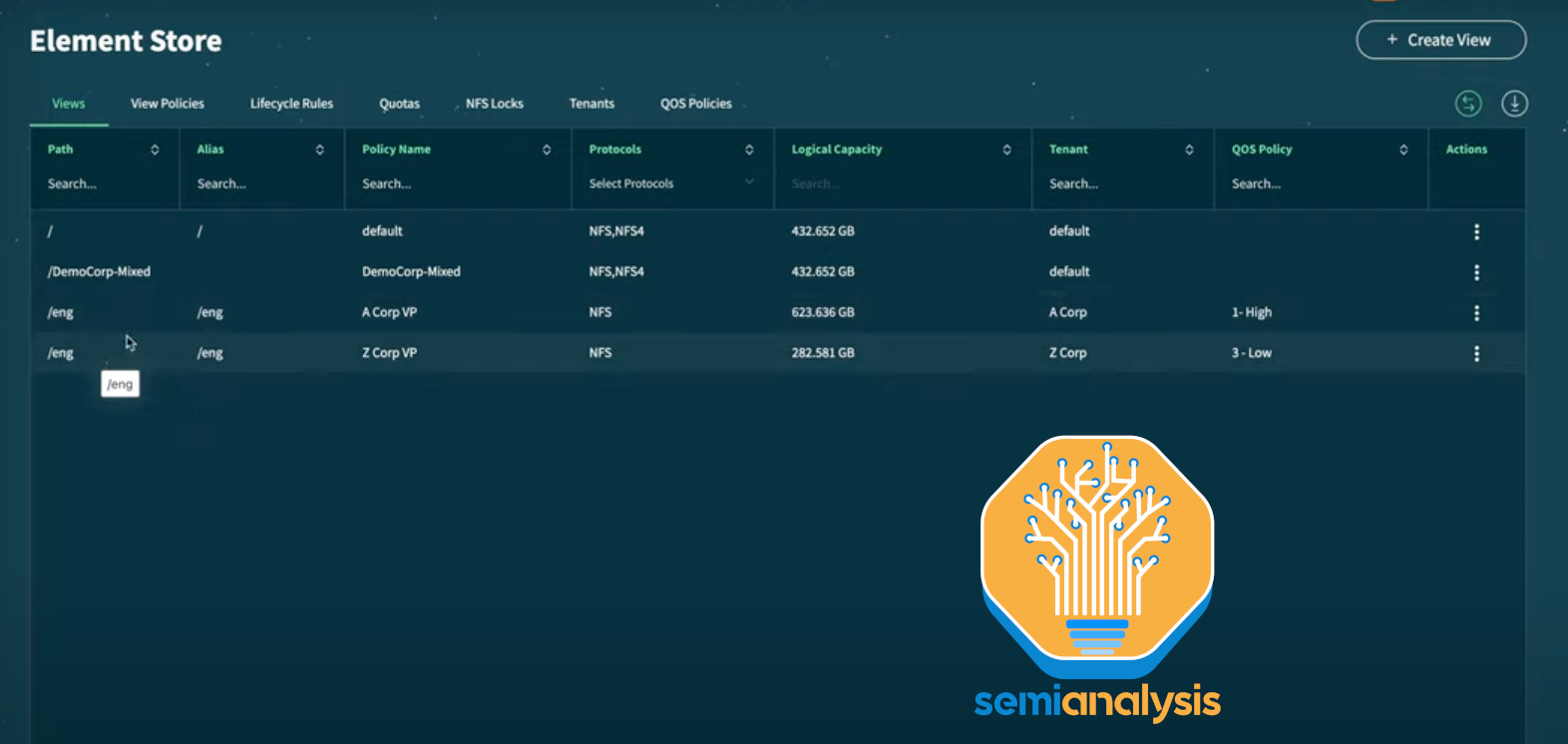
Multi-tenancy is especially important when it comes to storage. Fortunately, storage is also quite simple to manage as the major storage providers in the AI space, Weka and Vast both support multi-tenancy as a first-class primitive.
Within Weka and Vast’s Data software, you can easily create Tenants (called Organizations in Weka) and set up an access control policy for each storage volume to be assigned to just one tenant. This software provides strong guarantees that if the policies are set up correctly, then each customer’s users will only be able to access their own storage volumes.
For H100 SXM, the lowest unit of compute is one server, which means that each server will only ever have one customer at a time. This means that it is possible to do bare metal deployments while still maintaining security. Bare metal is possible and is indeed common, but we do see that utilizing VMs has added benefits such as superior mean time to recovery, and stronger reliability.
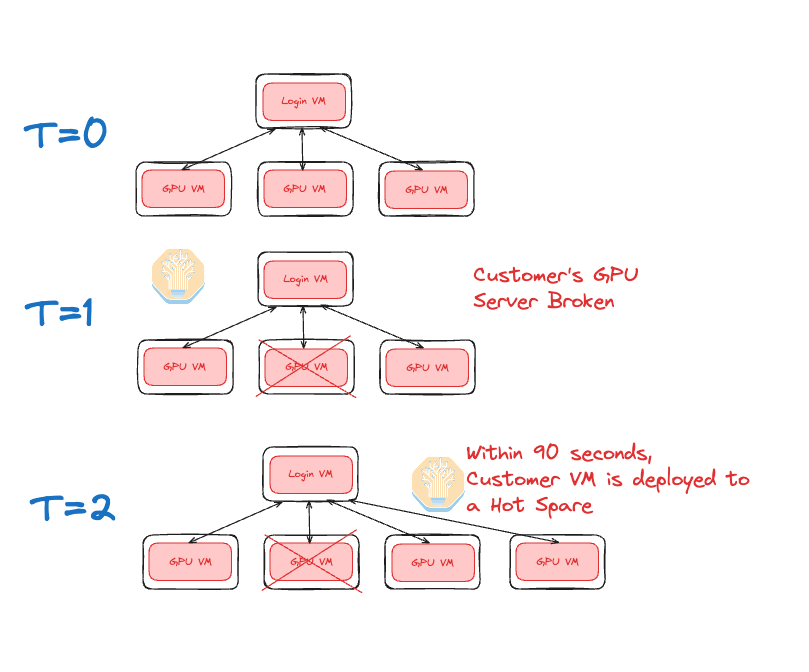
When using VMs, if a physical GPU server being used by a customer breaks, then the Neocloud is able to easily migrate or spin up a new VM for the customer on a hot spare.
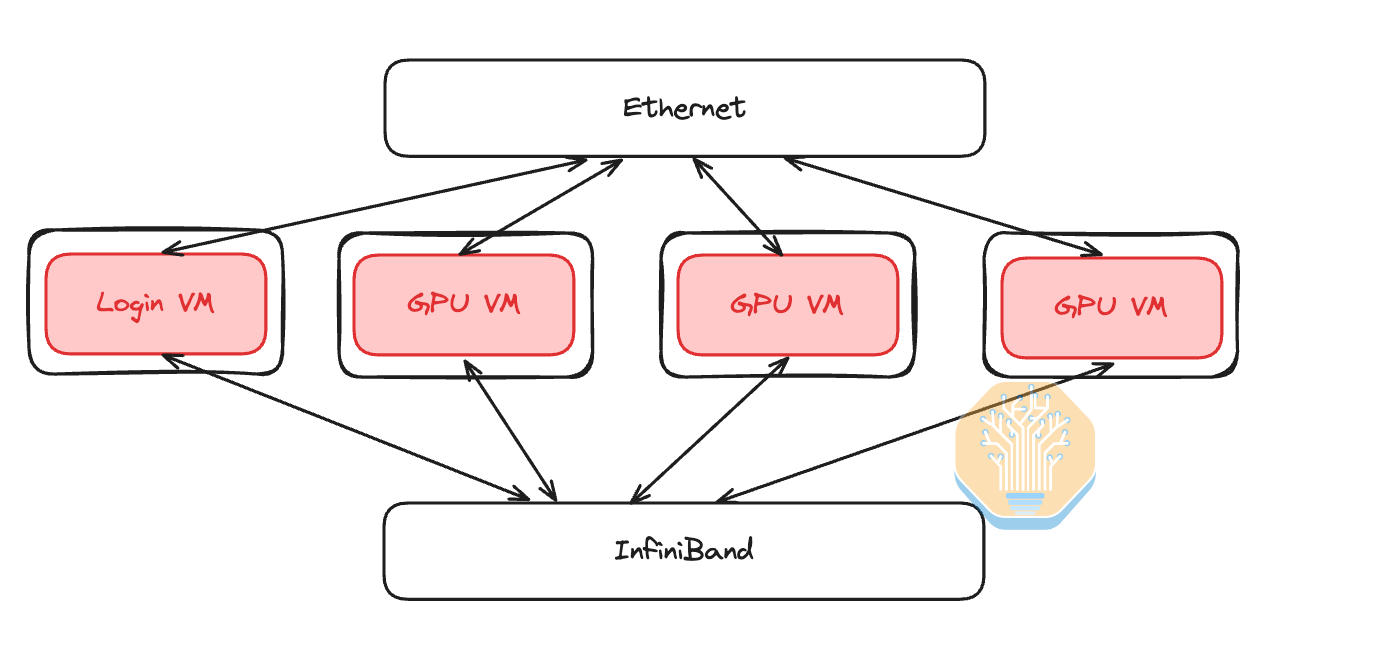
Creating virtual machines on GPU VMs can be done using an open-source hypervisor such as qemu-kvm, which will start your VM where you pin vCPUs to the physical CPUs and leave a couple cores unpinned to run the hypervisor.
You will also need to bind your vLAN ethernet interface to your GPU VM. Creating CPU VMs using the common hypervisor is a simple task that most Computer Science grads can do nowadays. To make a VM into a GPU VM, you also need to do PCIe Passthrough for your GPUs and InfiniBand NICs. Fortunately for Neoclouds, NVIDIA has yet to figure out a way to charge for PCIe passthrough on their GPUs and NICs. We have also seen Neoclouds use SR-IOV to create virtual InfiniBand NICs and pass though into the Virtual Machine instead of just the physical InfiniBand NIC, although using SR-IOV is not strictly needed.
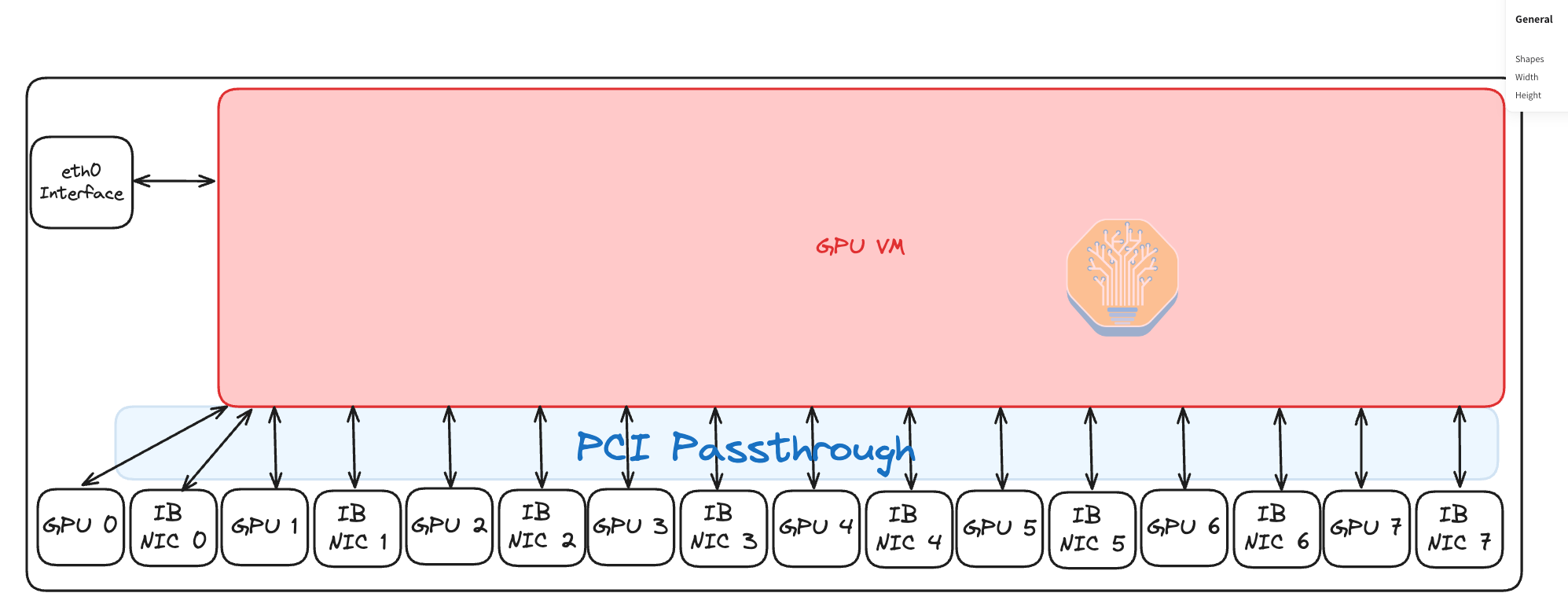
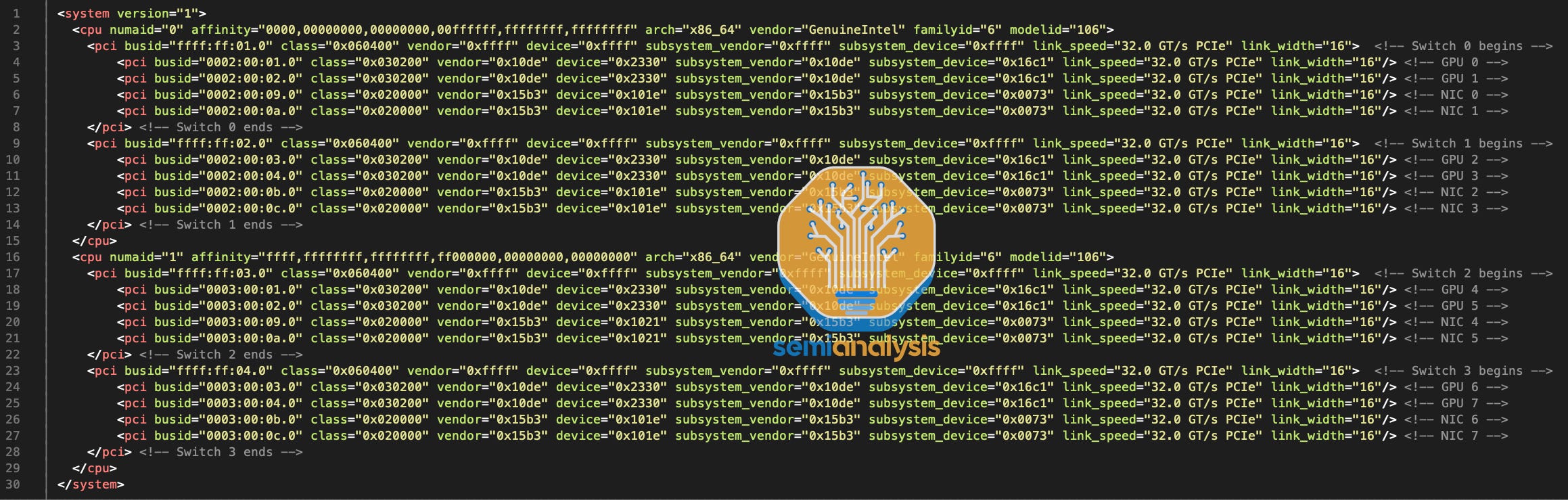
One additional step that you need to remember to carry out is to manually pass in the NUMA regions and PCIe topology file in /etc/nccl.conf through the NCCL_TOPO_FILE variable since NCCL and the Nvidia-drivers now operate inside that GPU VM and therefore are unable to auto detect the NUMA regions and the PCIe topology. Without this step, NCCL performance will operate at 50% the bandwidth of what it should be operating at.
One of the downsides of doing Virtual Machines compared to Bare Metal is that the CPU to GPU transfer bandwidth and latency is slightly slower due to the enablement of IOMMU. But we believe it is worth using Virtual Machines due to a faster mean time to recovery for the end user and because often HostToDevice (HtoH) transfers are overlapped with compute anyways so there may not even be a noticeable effect to the end user.
Since there are 1-2TB of CPU RAM, kvm-qemu hypervisor out of the box takes a long time for the VM to boot up. In contrast, with cloud-hypervisor, which has an optimization where the system prefaults the memory in parallel using multiple pthreads, which has the effect of reducing memory prefault times for 1TB from 80seconds to just 6 seconds. This optimization was created by Crusoe Cloud and was fortunately up streamed. From our testing, Crusoe’s VMs are able to boot up in less than 90 seconds.
The important benefit of a fast boot up is that when a customer’s GPU server inevitably fails, the Neocloud operator can very quickly deploy a VM to their hot spare node and add it into the customer’s SLURM cluster, allowing the customer to be able to very quickly resume training.
In terms of monitoring dashboards, at a bare minimum, we recommend having Nvidia Datacenter Manager dashboard through Grafana and Prothemeus, allowing users to track GPU temperatures, Power Usage and active XID errors.
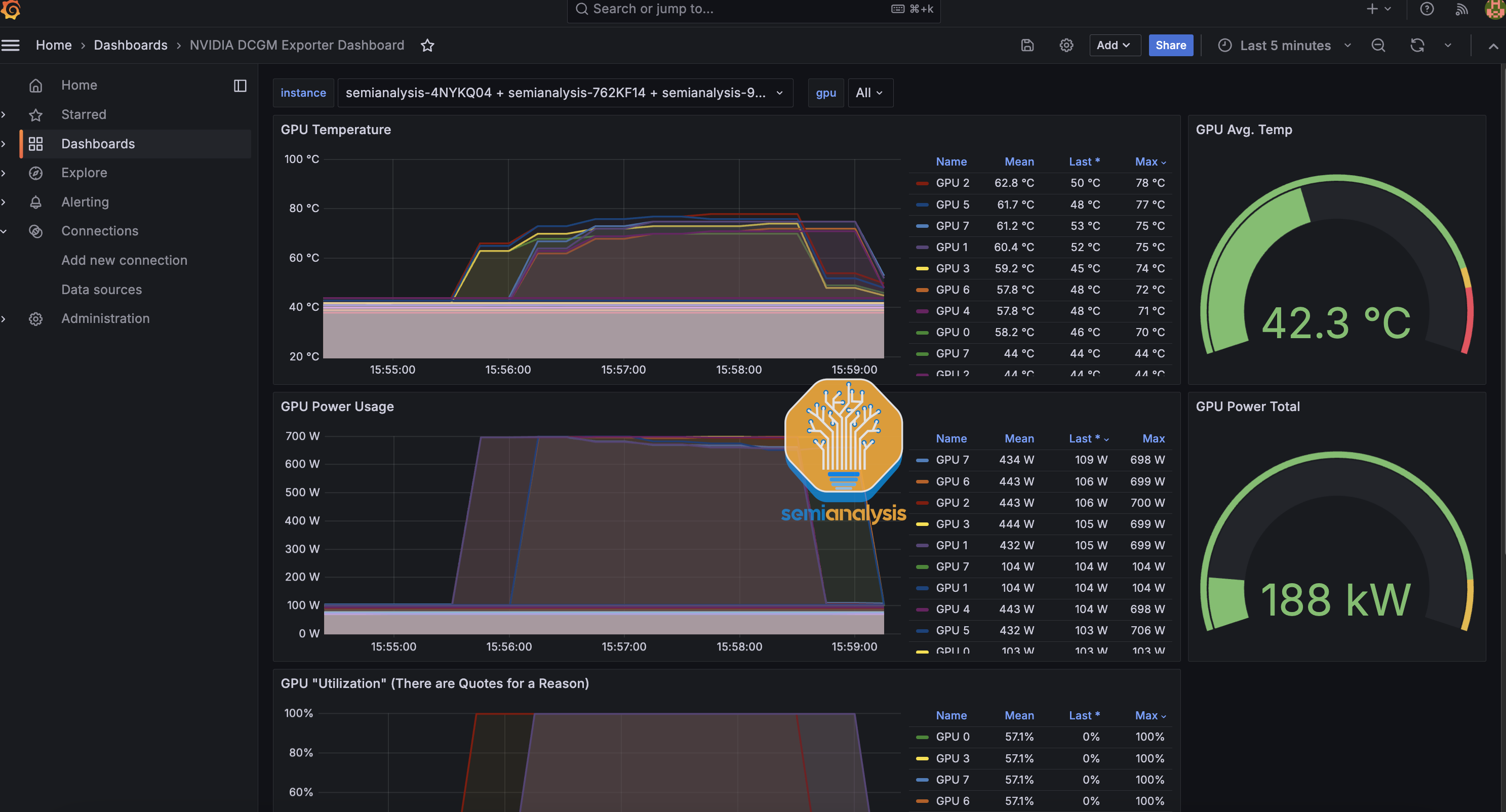
Furthermore, we also recommend that Neoclouds install ipmi-exporter to monitor overall fan speeds, temperatures and other BMC metrics. It is standard practice when running CPU deployments to have some sort of centralized dashboard with all of these metrics.
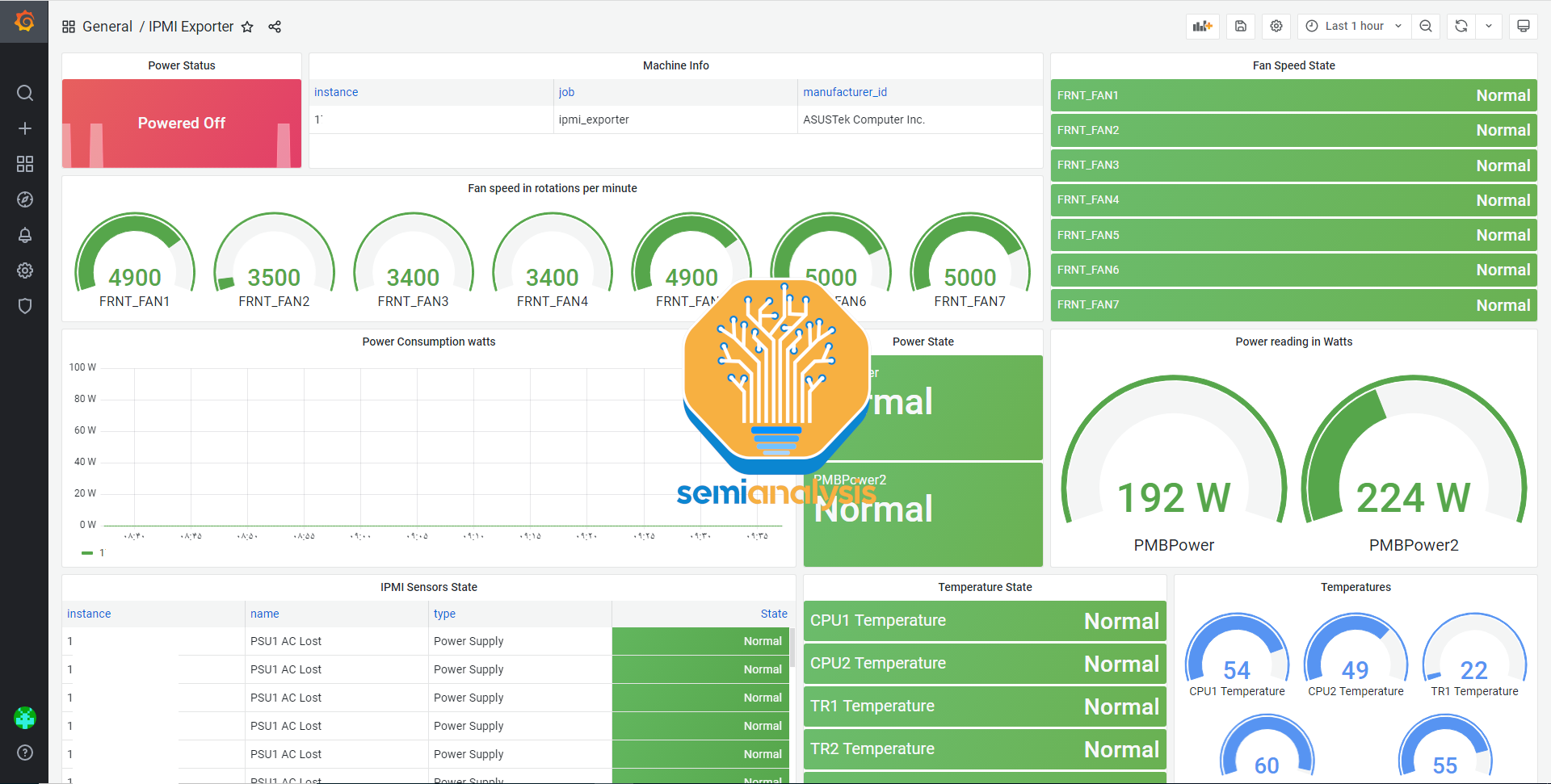
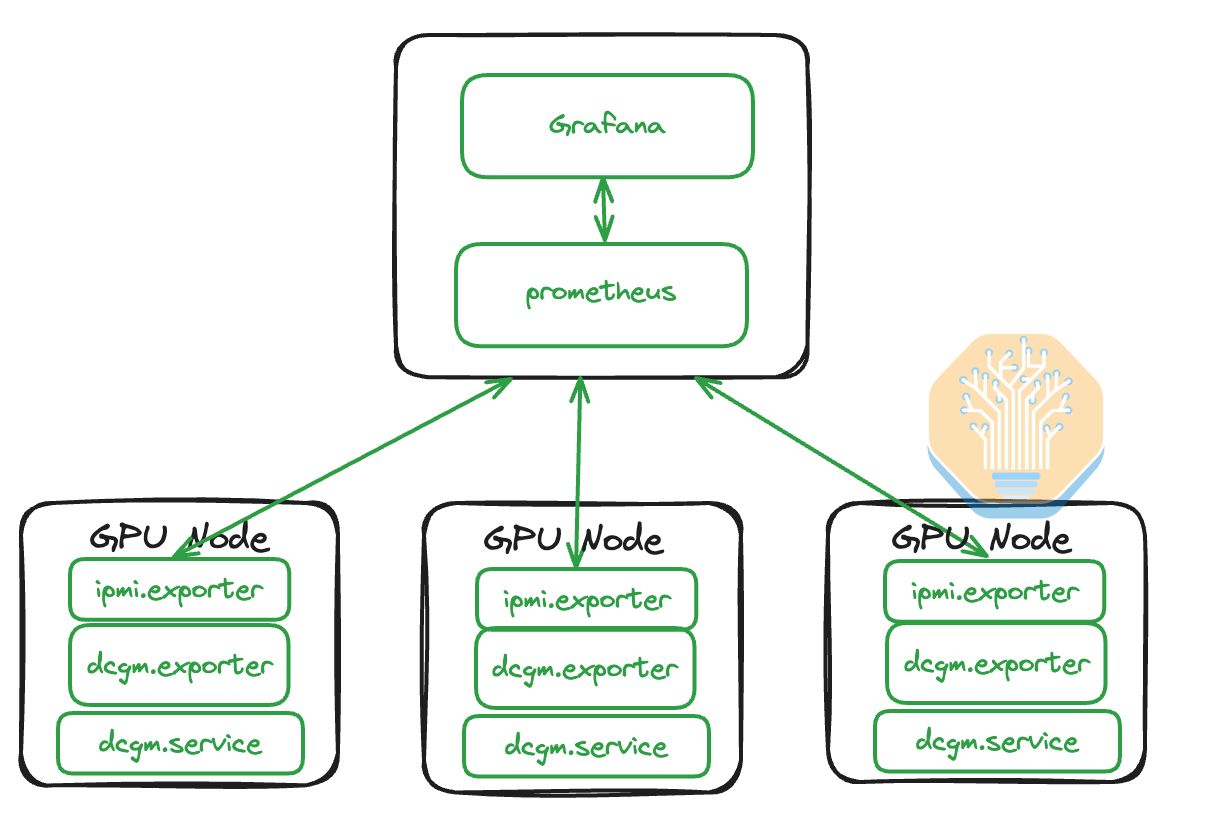
The software architecture for the monitoring involves having an IPMI exporter and DCGM exporter on each GPU node, then on a CPU management node deploying a Prometheus scraper to talk to the GPU exporters and store the data in an InfluxDB database. Next, the Grafana web server can be connected to Prometheus to visualize the collected data.
Advanced NeoCloud operators will also have a promtail logger that aggregates each server’s diagnostics messages (dmesg) logs. Two common concerning dmesgs that should be promptly flagged are Cable being Unplugged as well as NIC and/or transceiver temperatures overheating. Either of these messages probably indicates that you have a flapping InfiniBand Link that needs to be promptly addressed before customers start churning.
Another common error encountered is when GPUs reporting no errors at all through dmesg or through DCGM XID errors but output wrong matrix multiplication results. These errors are called silent data corruptions (SDC). The easiest way to figure out if there are SDCs on your GPUs is with the Nvidia DCGMI diagnostics level 4 tool (sudo dcgmi diag -r 4). The tool will catch 95% of the most common SDCs, but will unfortunately miss the remaining 5% of SDCs leading to very long debugging processes and very angry customers.
NCCL deadlocking and stalling are both very common issues that can cause a training job to stall for 30-35 minutes before PyTorch’s NCCL watch dog kills the whole training job. We believe that this is an area that Neoclouds can add value to their customers in if they add their own background NCCL checker to check active SLURM jobs and see if the jobs have been using more than 150W within the last 4 minutes. If power usage is below 150W, this probably means that NCCL is hanging and there is some sort of deadlock and a bot should probably automatically email the customer alerting them to restart their SLURM job.
Some of the most common problematic InfiniBand UFM error codes to track are 110 (Symbol error), 112 (Link downed), 329 (Link went down), 702 (Port is considered unhealthy), and 918 (Symbol bit error warning). We generally recommend that users immediately ping an engineer to investigate further should they encounter any of these above error codes when tracking the UFM error. Realistically, however, these issues will probably be already causing serious issues for many of the Neocloud’s customers who will already be spam pinging the Neocloud operator.
We highly recommend that Neocloud operators have a support ticketing system like Jira to keep track of all hardware failures and customer issues. Without a ticketing and customer management system, issues will fall through the cracks and cause increased customer churn.
Another feature that we don’t see many Neocloud operators use is SLURM topology.conf. The SLURM topology configure function will launch users’ SLURM training jobs and assign a SLURM_ID to each rank to reduce spine level traffic. For certain important messages, having a SLURM_ID assigned sub optimally will result in a 20-30% slowdown. We will talk more about this in our upcoming Nvidia NCCL and AMD RCCL collective communication deep dive.
In general, we recommend that you use nccl-tests to profile across your cluster and compare against Nvidia and your OEM’s reference numbers to see if there are any performance shortfalls or degradations.
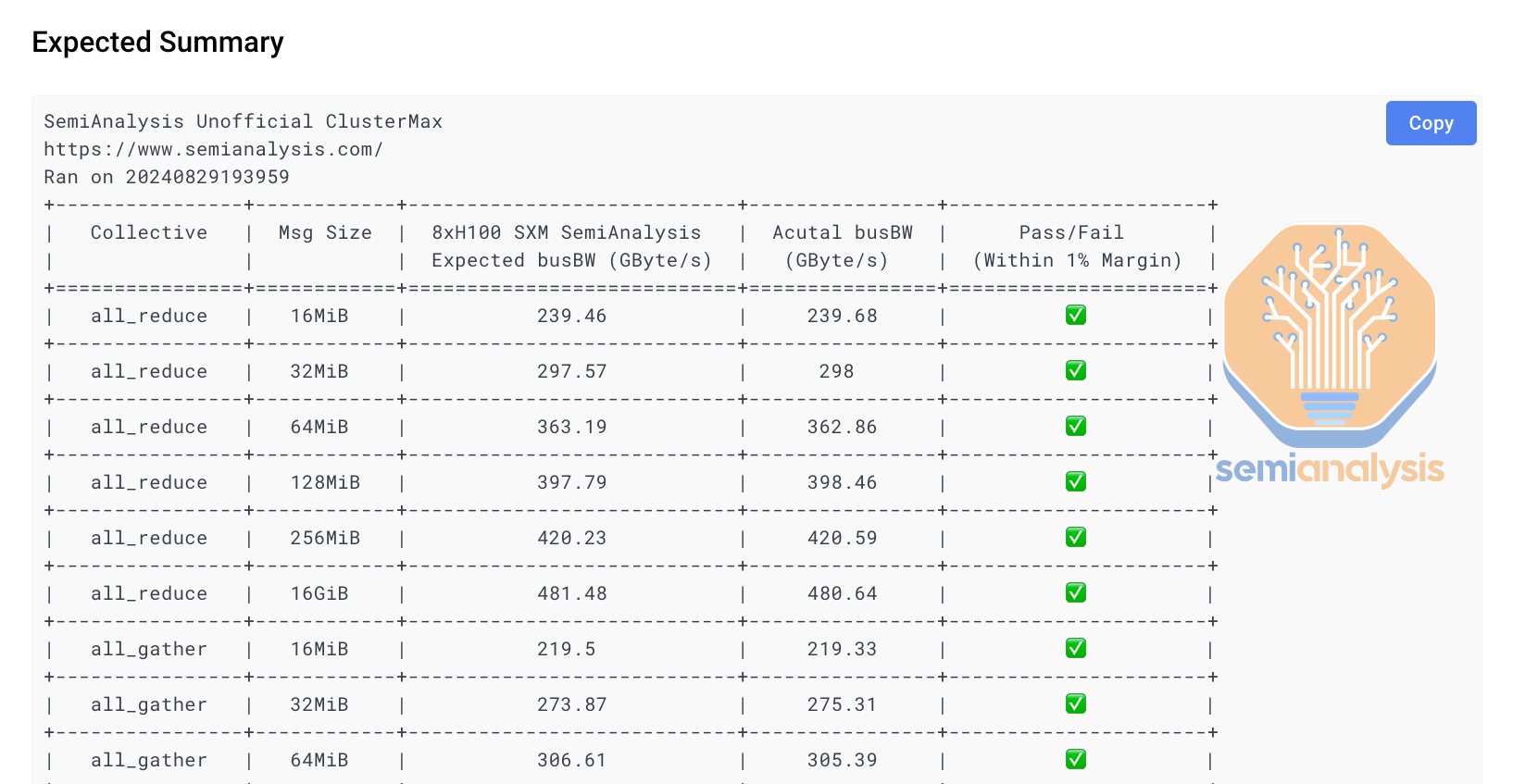
In order to make NCCL testing easy, we are developing a one liner function called ClusterMAX-NCCL to run and compare your cluster against a set of reference results.
In ClusterMAX-NCCL, we test against all the important message sizes from 16MiB to 256MiB for all the different types of collectives. We have recently launched a beta version of this tool that supports single node NCCL testing. Below is the one-liner to load and run ClusterMAX-NCCL:
docker run --gpus all --ipc=host --shm-size 192G -v $(pwd)/results:/workspace/results semianalysiswork/clustermax-nccl
If your node is configured properly, you should see results similar to the below:
Delivering competitive pricing, strong reliability and a properly set up cluster is the bulk of the value differentiation for most Neoclouds. The only differentiated value we have seen outside this set is from a Neocloud called TogetherAI where the inventor of Flash Attention, Tri Dao, works. TogetherAI provides their GPU customers a set of exclusive hyper optimized CUDA kernels that are made to be easily integrated into the customer’s existing training code, thus providing the customer with a quick 10-15% performance increase in training throughput.
Basically, by being able to speed up training by 10-15%, the customer can save 10-15% of their GPU spending or alternatively take the same GPU dollar budget and train their model on 10-15% more tokens leading to a model performance boost. We don’t believe the value created by Together can be replicated elsewhere without cloning Tri Dao.
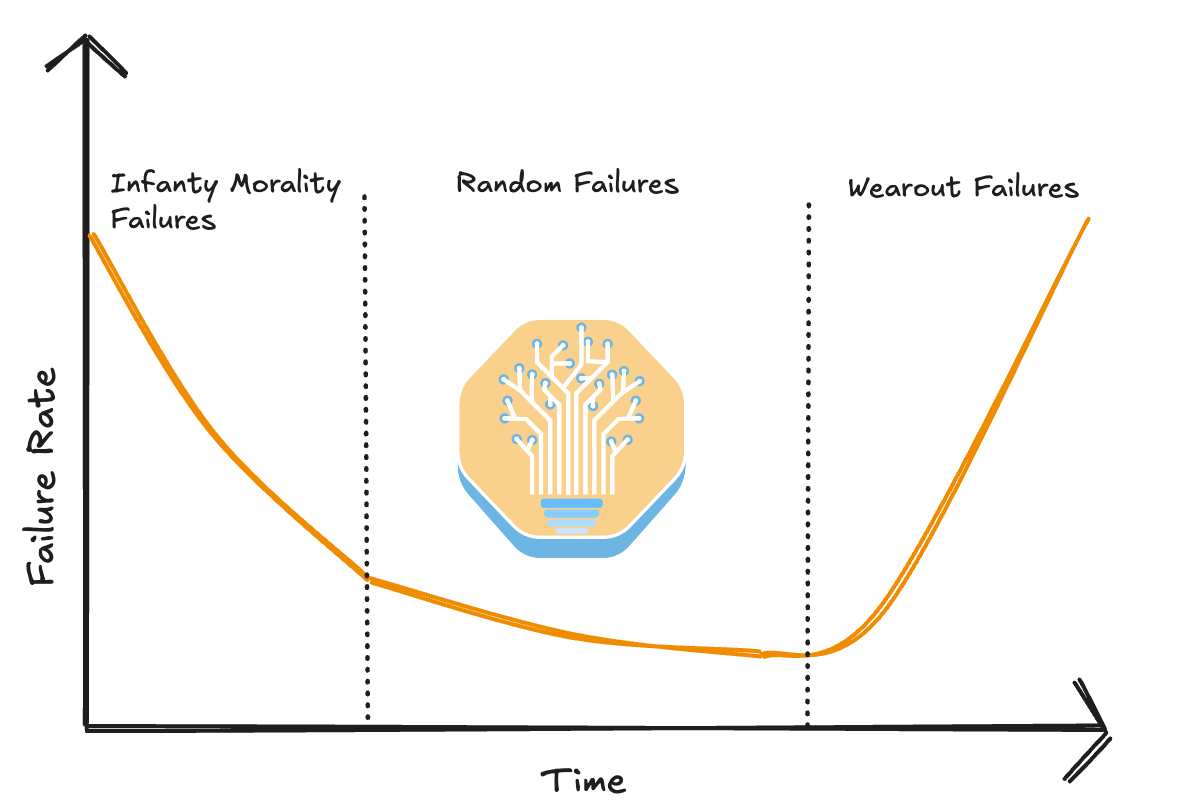
Cluster deployments typically leverage OEMs’ rack scale integration and deployment teams. These teams will integrate and test at the individual server level and at the cluster wide level during which networking testing will be carried out at OEMs’ integration factory. We recommend that the cluster wide high temp burn in should last at least 3-4 weeks to catch all the infant mortality related failures among the node’s components. It is extremely common for integration teams to pitch using LINPACK as their burn in and acceptance process, but we don’t believe that this is a very good test as LINPACK does not utilize the network much nor does it sweat the GPU’s HBM memory very much, instead only utilizing and testing the GPU’s FP64 cores. ML Training by contrast is very network, HBM and BF16/FP16/FP8 tensor core intensive and as such, we believe that a burn in and acceptance test that actually burns in related components is needed.
After the integration and burn in is completed at the integration factory, the OEM will pack up all the racks and cabling to deliver to the Neocloud’s datacenter, after which it will take another two weeks to deploy the cluster into this colocation data center. We recommend Neoclouds conduct another 2-3 day burn-in/acceptance test once the cluster has been set up on site even though the integration factory burn in has already been carried out. This is to make sure that no hardware was damaged during transportation or on-site deployment. A very common issue that crops up is flapping InfiniBand links due to dust on the fiber connection endpoints that accumulated during transportation and setup. The fix to solving this is to clean the fiber ends of the endpoints that are flapping. Sometimes there are more deep issues though that must be found and solved.
Day to day operations at Neoclouds mostly consists of whacking moles one after another. Having good internal management and debugging tooling will make this process run smoothly and even quite satisfying/enjoyable, but a lot of times at Neoclouds, there are not enough engineers to build these tools as ironically most of the engineers’ time will be spent whacking moles instead of building better mole whacking tools.
Some of the most common moles that will pop up around the cluster are flapping IB transceivers, GPUs “falling off the bus”, GPU HBM errors, and SDCs. Most of the time, these issues can be solved by just simply initiating a hard rebooting of the physical server or in many cases building a UI button or teaching the customer to hard power cycle the server themselves. In other cases, the resolution to the issues is to unplug and plug back in the InfiniBand transceiver or to clean the dust off of fiber cables. Other cases will require calling up the OEM or system integrator for a warranty RMA to replace the entire server completely.
As mentioned above, failures are very common during the early phase of a Neocloud cluster as most Neoclouds do not burn in their cluster before giving them to customers. As Yi Tay noticed, clusters that do not do burn are orders of magnitude worse when it comes to reliability than clusters that do conduct burn in testing.
This is another dimension where TogetherAI and Crusoe score strongly as they are some of the few Neoclouds that do multiple weeks long burn in prior to handing over clusters to customers. Furthermore, companies that have hired and retained people that have years of prior experience operating Nvidia GPUs and InfiniBand Networking will tend to encounter much lower failure rates since a lot of knowledge on setting up reliable clusters is part of an unwritten Tribal knowledge base on how to properly debug and prevent errors from happening for AI Clusters.
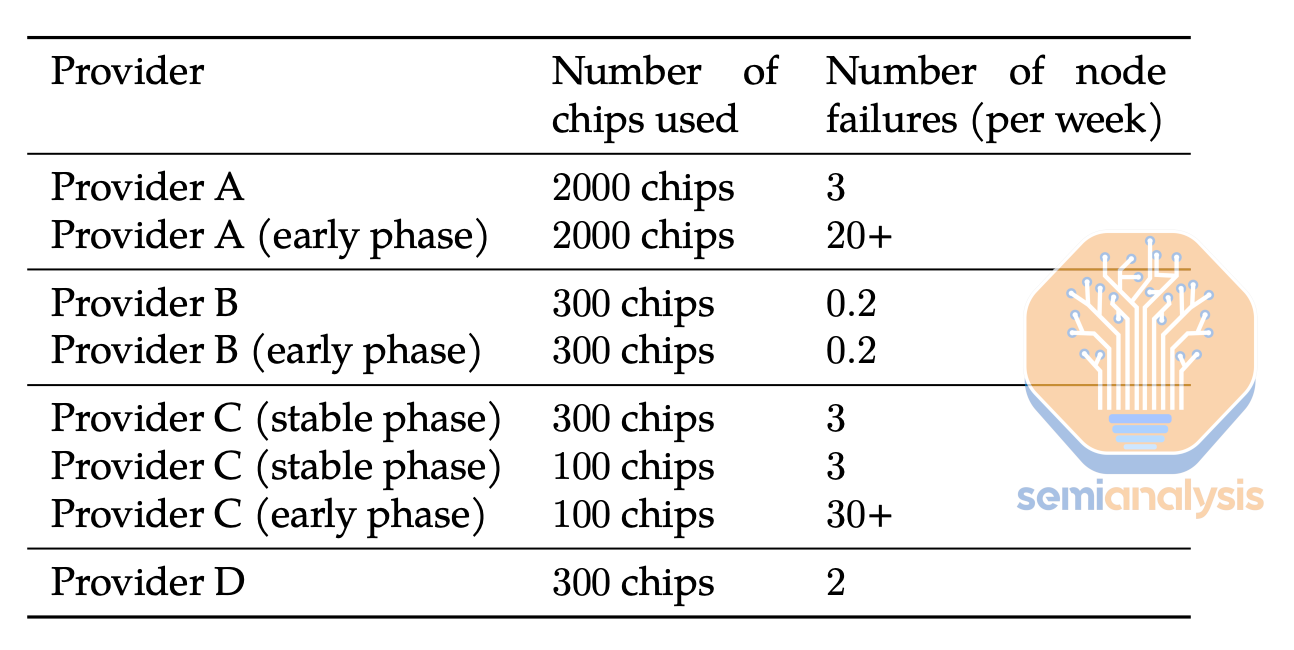
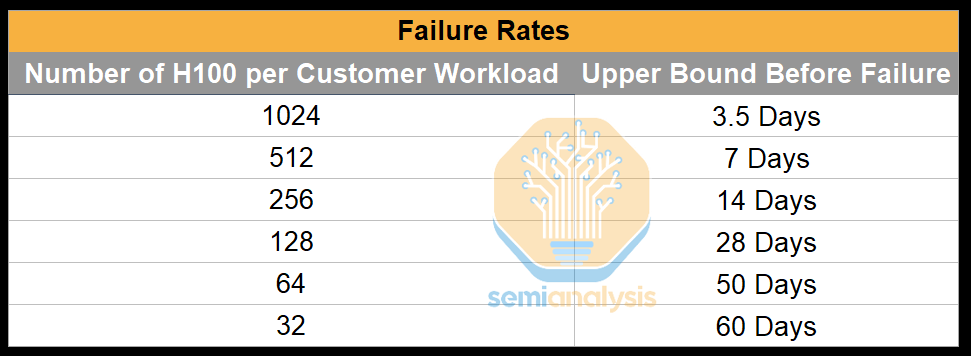
We see that a top tier H100 operator typically experiences a mean time between failures of 7 days for a cluster that has 512 H100s. For these top tier operators, most of the time, failures are easily fixable by just restarting the node.
We will now turn to the second part of our deep dive in which we will focus mainly on the economics of and business case for AI Neoclouds. The analysis here will be particularly useful for investors and business strategy analysts but can also provide some insights to buyers to better understand the pricing dynamics and economics in effect here. We do think that all managers, engineers, customers and investors of Neoclouds should understand and internalize the AI Neocloud deployment deep dive in Part 1 as well.