Accelerate chip-design verification process by running Siemens EDA Calibre on AWS – AWS Blog
Amazon is also a fabless semiconductor company. Several tapeouts are completed every year that result in products like Kindle, FireTV, Echo, etc. Amazon Web Services (AWS) does its inhouse semiconductor design for its data center operations through its internal team at Annapurna Labs. AWS Graviton, an ARM based CPU as well as AWS Trainium and AWS Inferentia chips used in high performance AI/ML processing are a few of the flagship product lines launched through Annapurna.
AWS and Siemens EDA entered into a Strategic Collaboration Agreement (SCA) in July 2023 to accelerate the migration of EDA workloads on AWS. Through this partnership, the companies developed what are known as Cloud Flight Plans, a set of best practices, infrastructure-as-code scripts and other best known methods or BKMs (including this document) to help semiconductor customers quickly and efficiently deploy and run their EDA workloads on AWS.
Siemens EDA, in cooperation with AWS, conducted a series of benchmarks on Annapurna production designs, exercising multiple Calibre flows including nmDRC and nmLVS. This paper presents findings, conclusions, and recommendations based on these runs, plus a set of general BKMs for getting the best return from running Calibre in the cloud. CAD, DevOps and IT engineers will find these studies valuable.
“Through the proof-of-concept exercise with Annapurna, we have validated the significant performance improvements that can be gained when running Calibre on AWS. Our measurable results from this POC can be seen by customers with a proven methodology to quickly deploy and run their Calibre flows on AWS using Siemens Cloud Flight Plans. With the virtually infinite capacity on AWS, customers can seamlessly scale to the optimum number of cores and thereby overcome any compute infrastructure constraints within their data centers. This will allow customers to perform more analysis for a higher quality design and/or mitigate tapeout schedule risks and bring their products to market faster.” – Michael White, Senior Director Siemens EDA.
A Reference Environment Toolkit is used to manage and launch Calibre runs inside the secure chamber on AWS, a Virtual Private Cloud (VPC) network. AWS ParallelCluster is used to deploy the AWS services, including the Amazon Elastic Compute Cloud (EC2) instances, the Amazon Elastic File System (EFS) and FSx filesystems as well as a few other AWS services that are used in the chamber. Once the chamber is fully deployed, users submit their jobs through queue manager commands that they enter on the head node. The SLURM scheduler manages the scaling up and down of compute nodes to meet the job’s processing requirements.
The following table provides the specifications of the full-chip design from Annapurna: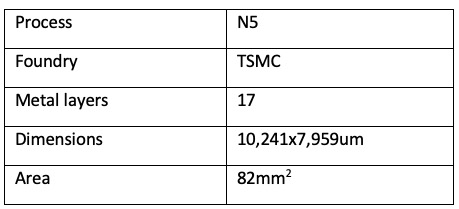
The following table provides the specifications of the EC2 instance used in the study:

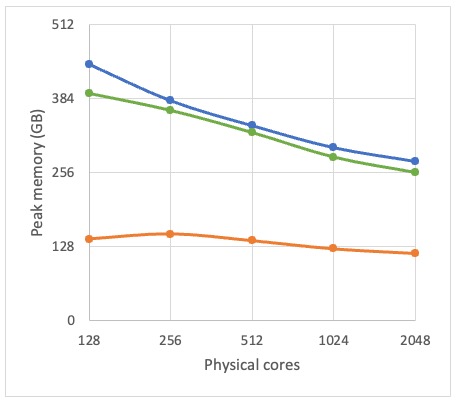
Figures A and B show the results from Calibre nmDRC testing on the N5 design. Figure A shows run time in hours, and Figure B shows peak remote memory usage in GB. All runs used MTflex, which is one of Calibre’s distributed processing modes. These runs used a homogeneous cluster –the same machine types for the primary as for the remote nodes (r6i.32xlarge instances).
The horizontal axis shows the number of remote cores, which were doubled with each subsequent run. Each run used a consistent 64 core primary machine.
The blue is the baseline run – these runs used Calibre 2021.1 (the same version that Annapurna used in production on these designs) with stock rules from TSMC.
The green line shows a more recent version of Calibre – 2023.1 – with rules that Calibre Product Engineers optimized. For these runs, instead of reading the data from an OASIS file, the design data was restored from a previously saved reusable hierarchical database, or RHDB, which, in this case, saved about 20 minutes per run. The dotted line shows the percentage time saving between these two sets of runs.
The orange line is for Calibre nmDRC Recon(naissance), which automatically selects a subset of the foundry rules to run. Siemens EDA always recommends that customers run Calibre nmDRC Recon on dirty designs before committing to a full Calibre run. This helps find the gross errors in the design very quickly, so they can be eliminated with short cycle times.
The peak memory plots show that there was plenty of headroom for physical memory – each remote had 1TB RAM.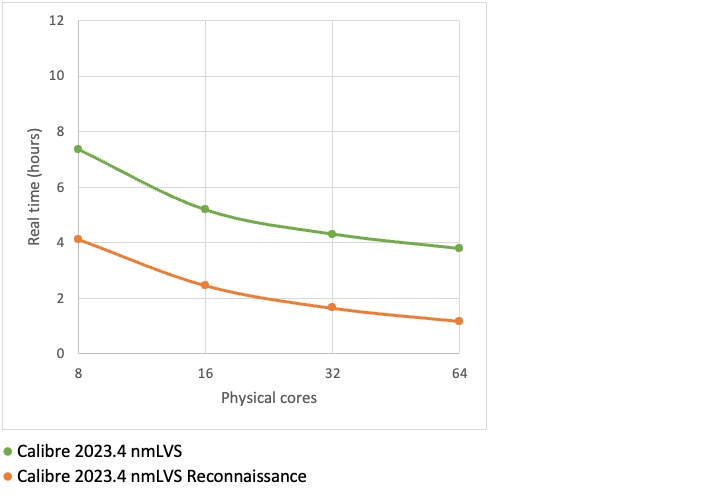
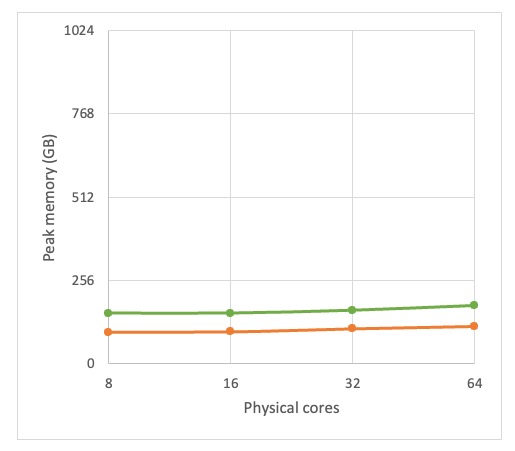
These Calibre nmLVS runs were done on a single r6i.32xlarge machine using the -turbo setting, i.e. multi-threaded. The host machine had 1TB memory, which turned out to be way more than was needed, so a c6i.32xlarge machine would have been sufficient for this job.
These results are for the complete ruleset (green line) and for Calibre nmLVS (Recon)naissance (in orange). The results demonstrate good scalability right across the number of cores that were used for the tests – the best option in this case would be to run as an exclusive job on a c6i.32xlarge host (64 physical cores, 256GB memory).
This section describes specific findings from the Annapurna benchmarks, and recommendations based on these observations.
Calibre nmDRC Recon
Calibre nmDRC Recon runs in a fraction of the time for a fraction of the cost of running the complete set of rules, and helps you get to the gross errors in an early-stage design quickly. The Recon feature of Calibre nmDRC automatically selects a subset of design rules that are most applicable during the early stages of a design. This helps find issues early, enabling design teams to quickly debug and reduce future iteration times and the total number of iterations needed.
Memory capacity generally drives virtual machine selection
Memory is typically the key factor that decides what kind of machines are needed to run Calibre in the cloud. The primary machine will generally use more memory than any of the remote machines. Memory recommendations are a function of the technology node. More advanced nodes require more. At 7/5nm, the Siemens EDA recommendation is to use 16 gigabytes per core for Calibre nmDRC runs. The r6i instances are perfect in this respect – the r6i.32xlarge instances have 64 physical cores and 1TB memory (64 x 16 = 1024). All of our DRC tests on the Annapurna designs peaked at less than half this amount of memory.
Use a recent version of Calibre
Runs described in this paper used Calibre version 2023.4, which was the most recent release available at the time of running the benchmarks. This new version improved overall performance as well as scalability for high numbers of cores versus previous releases.
Reusable hierarchical database
At the beginning of a Calibre nmDRC run, the first step involves reading the OASIS or GDS design file and creating a hierarchical database (HDB). This HDB is essential for the Calibre nmDRC software to efficiently execute a given rule deck and design. Calibre verification has introduced a reusable hierarchical database (RHDB), which can be saved on disk and used as the basis for later runs. The benefit of using an RHDB is that it significantly reduces the time taken to read the file compared to an OASIS or GDS file. Building the RHDB requires a lower number of CPU cores, but is generally the most memory-intensive step of the Calibre flow.
Split the rule decks
Siemens EDA works closely with foundry partners to balance Calibre rule decks so that they scale well across large numbers of cores and allow Calibre customers to complete multiple design turns per day. However, starting at 3nm, some rule checks scale to larger numbers of cores than others. For this reason, foundries are beginning to provide “split” rule decks for DRC operations. For example, foundries might split the complete set of DRC checks into one rule file for voltage dependent rules, another for electrostatic discharge (ESD) rules and latch-up checks, and a third for the remainder of the “core” DRC checks. Each of these rule sets can be run independently and in parallel with the others.
Choose the right number of cores for the job
The benchmarks show an optimal point in the performance scaling curves between 500 and 1000 remote physical cores. This point represents the best balance between performance (throughput) and compute cost. This number is design and process dependent. In practice, we expect Calibre customers to use at least 500 remote cores for full-chip, advanced node DRC verification.
The cloud gives unlimited access to machines that are tuned for EDA workloads. It allows users of advanced EDA tools to work how they want, launch jobs whenever they want, and use as many resources as needed to get the job done. The same applies in a production or tape out situation. There are no resource constraints; for example, it’s not necessary to wait for a DRC run to finish and free up resources before starting an LVS run. It is advantageous to run multiple jobs on multiple flows in parallel, because this accelerates design cycles and the cost is the same as running in a serial fashion.
Cloud computing provides an opportunity to accelerate initial concept (IC) design time to NPI (new product introduction), especially when you consider growth in advanced nodes computing requirements. As a Fabless semiconductor company, Annapurna Labs relies exclusively on AWS cloud for the expansive and elastic compute power for building sophisticated SoC. “Using Siemens EDA Calibre tools in our IC Physical Verification processes, especially at burst times, dramatically improved our capabilities to run DRC efficiently by taking advantage of AWS distributed cloud infrastructure and services,” said Shahar Even Zur, Vice President of Engineering at Annapurna Labs.
For further information, contact your AWS sales representative or visit Siemens Calibre nmDRC and AWS EDA workloads.
Siemens EDA, a segment of Siemens Digital Industries Software, is a technology leader in software and hardware for electronic design automation (EDA). Siemens EDA offers proven software tools and industry-leading technology to address the challenges of design and system level scaling, delivering more predictable outcomes when transitioning to the next technology node.
Azim Siddique is a Senior Solutions Architect at AWS where he works with Enterprise customers on their Cloud adoption journey. Azim has 20+ years of experience working at large global organizations in the manufacturing and industrials domain, architecting and delivering innovative solutions at scale to generate business value. Azim is passionate about being part of transformational changes driven by technological innovation.
Chris Clee is a product engineer for Calibre Design Solutions at Siemens Digital Industries Software, with responsibility for cloud and high-performance compute solutions. His decades-long EDA career spans the gamut of the industry, from system-level design and functional verification to back-end physical IC tools and PCB design.