Blackwell của Nvidia được làm lại – Sự chậm trễ trong việc giao hàng và nền tảng GB200A được làm lại
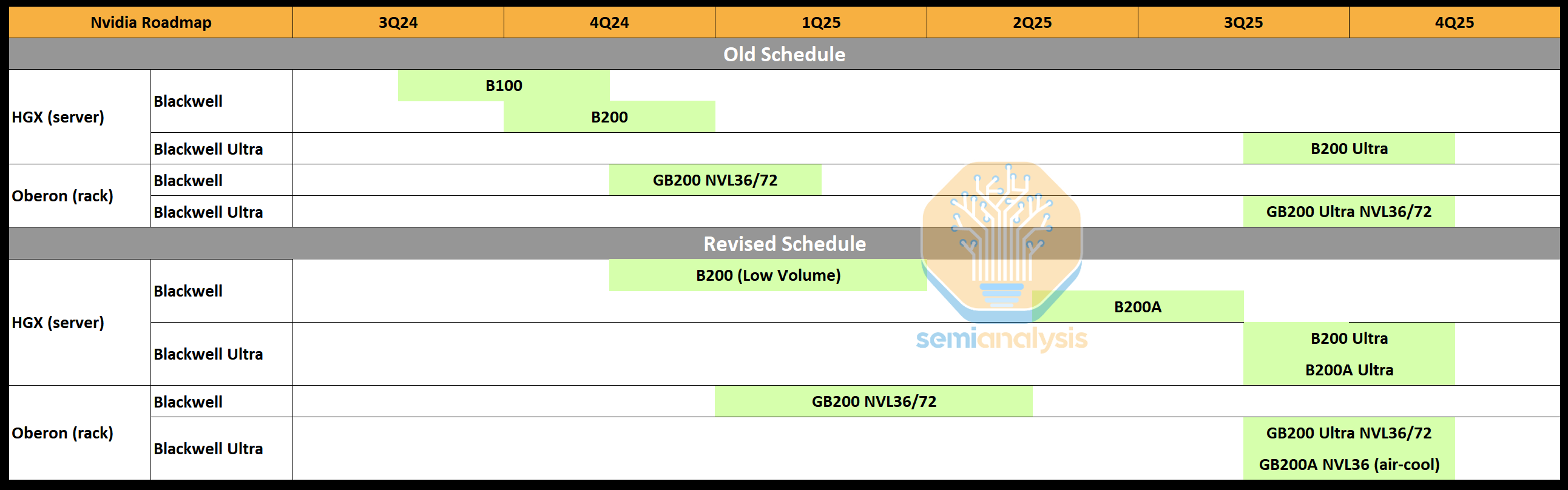
Nvidia’s Blackwell family is encountering major issues in reaching high volume production. This setback has impacted their production targets for Q3/Q4 2024 as well as the first half of next year. This affects Nvidia’s volume and revenue, as we detailed in the Accelerator Model on July 22nd. In short Nvidia’s Hopper is extended in lifespan and shipments to make up for a chunk of the delays. Product timelines for Blackwell are pushed out some, but volumes are affected more than the first shipment timelines.
The technical challenges have also sent Nvidia scrambling to create completely new systems that was not previously planned which has huge ramifications on dozens of downstream and upstream suppliers. Today we will go through the technical challenges Nvidia is facing, Nvidia’s revised timelines, and detail the system and component architecture of Nvidia’s new systems including the new MGX GB200A Ultra NVL36. We will also dig into the effects this will have for the entire supply chain from customers to OEMs/ODMs to Nvidia’s component suppliers.
The most technically advanced chip in Nvidia’s Blackwell family is the GB200, where Nvidia is making aggressive technical choices on multiple facets at a system level. The 72 GPU rack has a power density of ~125 kW per rack despite the standard for most datacenter deployments being at ~12kW to ~20kW a rack.
This is a compute and power density that has never been achieved before, and given the system level complexity needed, the ramp has proven challenging. Numerous issues have cropped up related to power delivery, overheating, water cooling supply chain ramp, water leakage from quick disconnects, and a variety of board complexity challenges. While these have sent some suppliers and designers across the supply chain scrambling, most of the issues are minor and not the cause of Nvidia’s reduction in volumes or major roadmap rework.
The core issue impacting shipments is directly related to Nvidia’s design of the Blackwell architecture. The supply of the original Blackwell package is limited due to packaging issues at TSMC and with Nvidia’s design. The Blackwell package is the first high volume design to be packaged with TSMC’s CoWoS-L technology.
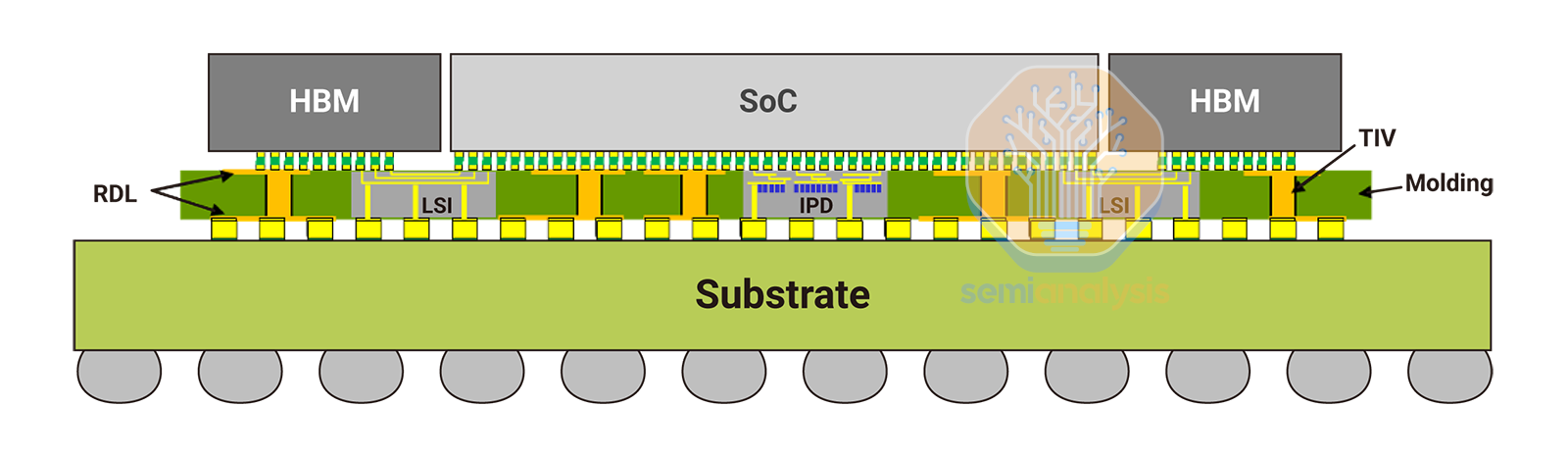
To recap, CoWoS-L uses an RDL interposer with local silicon interconnects (LSIs) and bridge dies embedded in the interposer to bridge communication between the various compute and memory on the package. Compare this to CoWoS-S which is on the surface, much more simple, a massive slab of silicon.
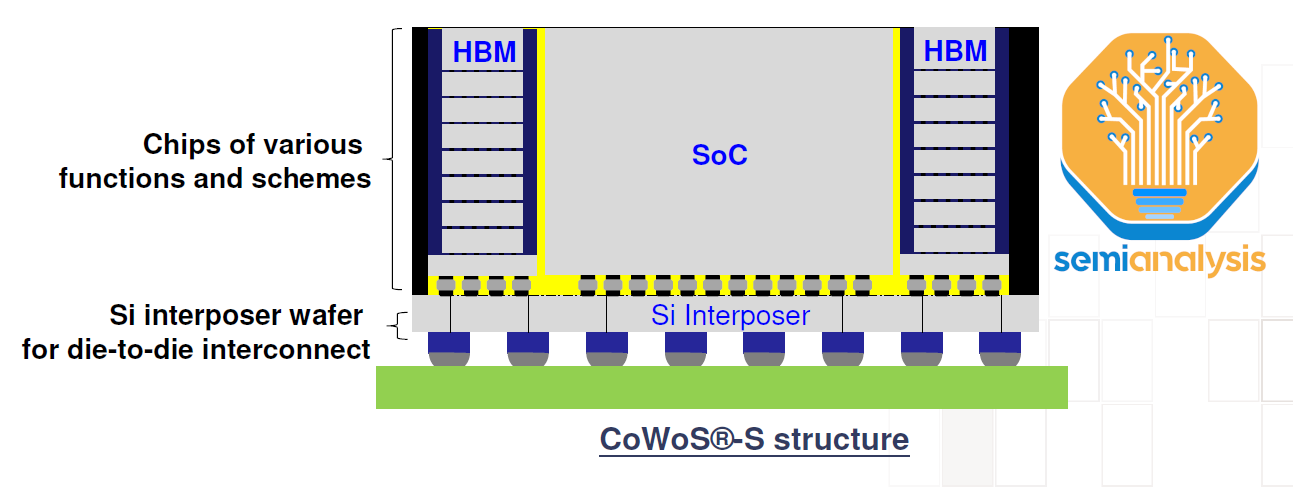
CoWoS-L is the successor to CoWoS-S due to the challenges with CoWoS-S package size growth and performance as future AI accelerators fit more logic, memory, and IO. TSMC has scaled CoWoS-S to ~3.5x reticle sized interposers with AMD’s MI300, but this is the practical limit. There are multiple gating factors, but the key one is that silicon is brittle, and handling very thin silicon interposers gets harder as the interposers get larger. These large silicon interposers also get more costly with more and more lithographic reticle stitching.
Organic interposers can address this as they are not as brittle as silicon, but they lack the electrical performance of silicon and as such do not provide enough I/O for more powerful accelerators. Silicon bridges (either passive or active) can be then used to supplement signal density to compensate. Furthermore, these bridges can be higher performance/complexity than the large silicon interposer.
CoWoS-L is a much more complex technology, but it is the future. Nvidia and TSMC aimed for a very aggressive ramp schedule to over a million chips a quarter. Consequently, there have been a variety of issues.
One is related to embedding multiple fine bump pitch bridges in the interposer and within an organic interposer can cause a coefficient of thermal expansion (CTE) mismatch between the silicon dies, bridges, organic interposer, and substrate, causing warpage.
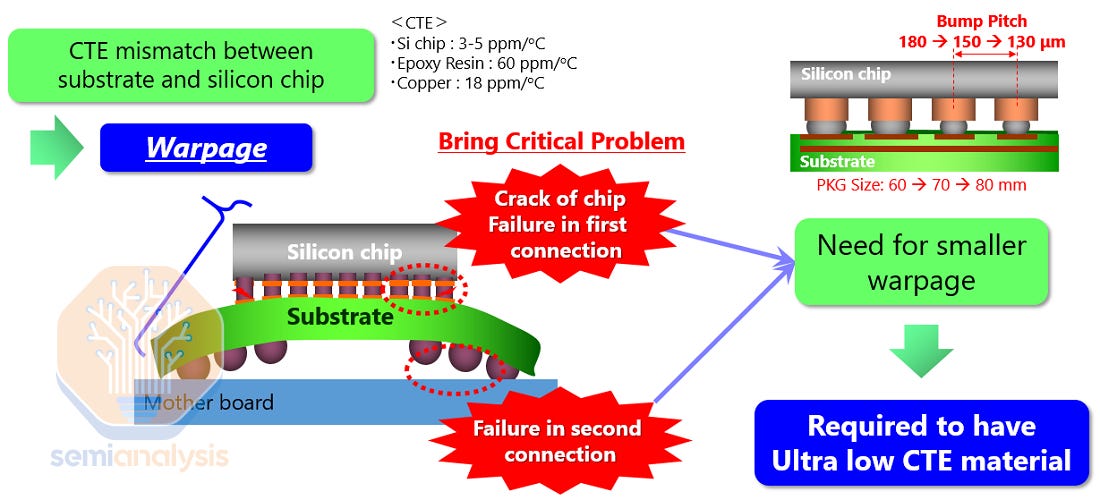
The bridge die placement requires very high levels of accuracy, especially when it comes to the bridges between the two main compute dies as these are critical for supporting the 10 TB/s chip-to-chip interconnect. A major design issue rumored is related to the bridge dies. These bridges need to be redesigned. Also rumored is a redesign of the top few global routing metal layers and bump out of the Blackwell die. This is a primary cause of the multi-month delay.
There has also been the issue of TSMC not having enough CoWoS-L capacity in aggregate. TSMC built up a lot of CoWoS-S capacity over the last couple years with Nvidia taking the lion’s share. Now with Nvidia quickly moving their demand to CoWoS-L, TSMC is both building a new fab, AP6, for CoWoS-L and converting existing CoWoS-S capacity at AP3. TSMC needs to convert the old CoWoS-S capacity as otherwise it would be underutilized and the ramp of CoWoS-L would be even slower. This conversion process makes the ramp very lumpy in nature.
Combine these two issues and it’s clear that TSMC will not be able to supply enough Blackwell chips as Nvidia would like. Consequently, Nvidia is focusing what capacity they have almost entirely on GB200 NVL 36×2 and NVL72 rack scale systems. HGX form-factors with the B100 and B200 are effectively now being cancelled outside of some initial lower volumes.
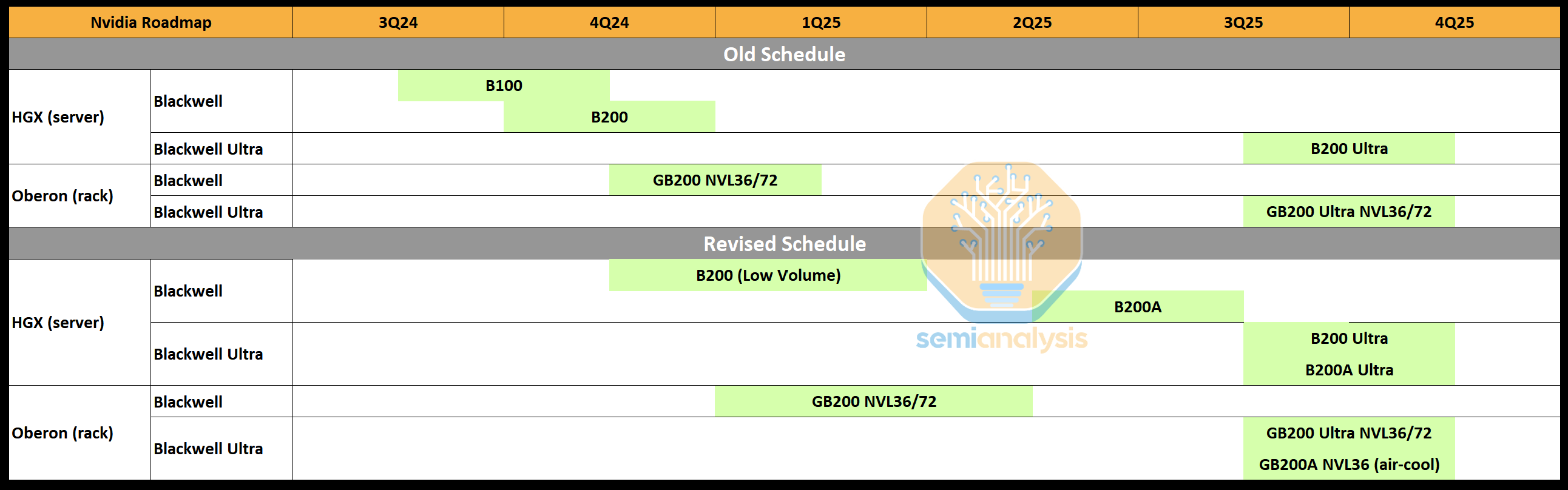
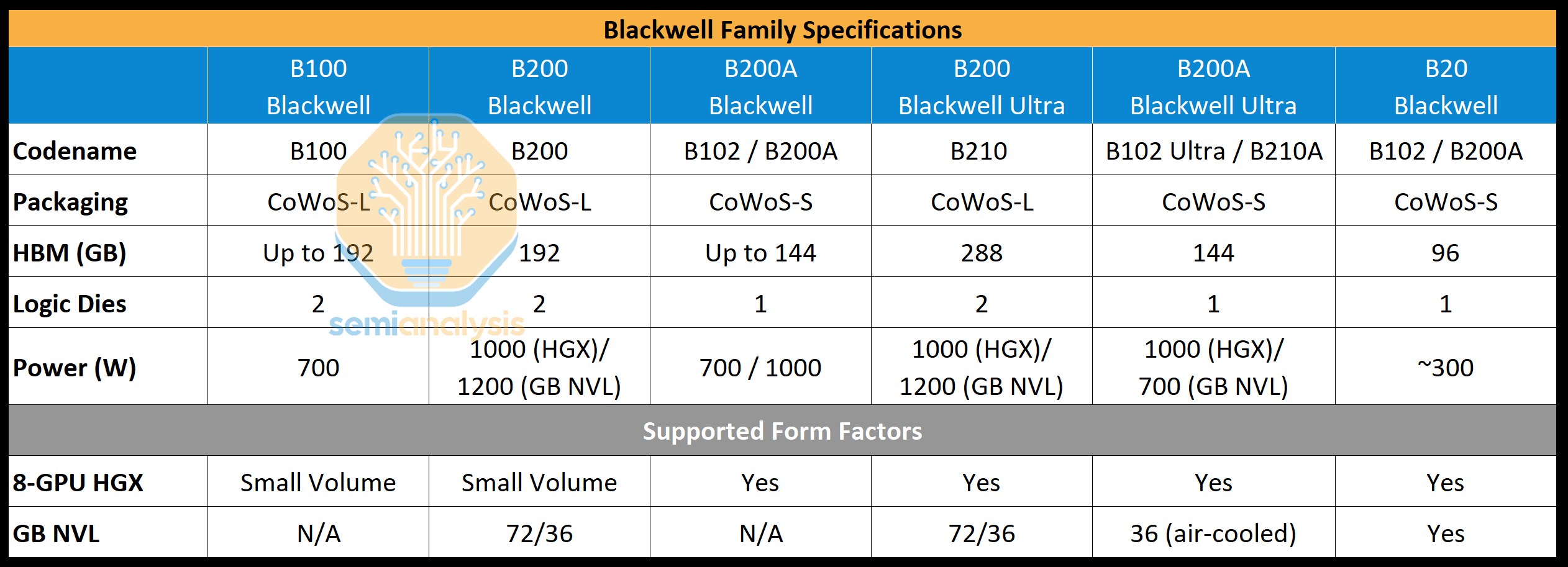
To satisfy demand, Nvidia will now be introducing a Blackwell GPU called the B200A based on the B102 die. Interestingly, this B102 die will also be used in the China version of Blackwell, called B20. The B102 is a single monolithic compute die with 4 stacks of HBM. Importantly, this allows the chip to be packaged on CoWoS-S instead of CoWoS-L, or even Nvidia’s other 2.5D packaging suppliers such as Amkor, ASE SPIL, and Samsung. The original Blackwell die has a lot of shoreline area dedicated to C2C I/O which is unnecessary in a single monolithic SOC.
The B200A will be used to fulfil demand for lower-end and mid-range AI systems. and will be replacing the B100 and B200 chips for the HGX 8-GPU form factors. It will come in a 700W and 1000W HGX form factor with up to 144GB of HBM3E and up to 4 TB/s of memory bandwidth. Notably this is less memory bandwidth than H200.
Turning to Blackwell Ultra, the mid-generation enhancement of Blackwell, the standard CoWoS-L Blackwell Ultra will be known as the B210 or B200 Ultra. Blackwell Ultra contains both a memory refresh going to up to 288GB of 12 Hi HBM3E and a performance enhancement in FLOPS, up to 50%.
The B200A will also have an Ultra version. Notably there will be no memory upgrade for it, though the die may be redesigned to lift FLOPS. The B200A Ultra also introduces a brand new MGX NVL 36 form factor. The B200A Ultra will also come in the HGX configuration just like the original B200A.
For the hyperscaler market, we believe that GB200 NVL72 / 36×2 will continue to be the most attractive as it has the highest amount of performance/TCO for models exceeding 2 trillion parameters during inference. With that said, Hyperscaler customers may still need to buy the MGX GB200A NVL36 if they are unable to get as much GB200 NVL72 / 36×2 allocation as they would have wanted. Furthermore, in datacenters with lower power density or that lack of permitting / access to water for liquid cooling retrofit, the MGX NVL36 looks more attractive.
HGX Blackwell servers will still be bought by hyperscalers as it’s the smallest unit of compute that is useful for renting to external customers, but it will be purchased in much lower volume than before. For small models, the HGX is still the best performance/TCO as these models don’t require a bunch of memory and can fit within a single memory coherent domain of NVL8.
HGX Blackwell’s perf/TCO also shines when doing training runs with less than 5,000 GPUs going towards a training workload. With that said, the MGX NVL36 is the sweet spot for many next generation models and is more flexible infrastructure generally and as such it is the superior choice in many cases.
For the neocloud market, we believe that most customers will not be buying GB200 NVL72 / 36×2 due to the high complexity of finding colocation providers that support liquid cooling or high power density with sidecars. Furthermore, most neoclouds are further back in the line generally vs hyperscalers for the limited GB200 NVL72 / 36×2 volumes.
We believe that the largest neoclouds such as Coreweave that both do their own self-build datacenters / retrofits and have larger customers will opt for GB200 NVL72 / 36×2. For the rest of the neocloud market, most will opt for HGX Blackwell servers and MGX NVL36 as these can be deployed using only air cooling and lower power density racks. Currently most neocloud deployments are for Hopper and are at a power density of 20kW/rack. We believe that it is possible for neoclouds to deploy MGX GB200 NVL36 as this only requires 40kW/rack of air cooling.
By using cold aisle containment and skipping rows in the datacenter, 40kW per rack is not too difficult to deploy. At the neocloud scale, the neocloud operators and the customers of neoclouds don’t really tend to think of performance per TCO for their specific workloads, but instead, they just try to procure whatever is most hyped at the moment. For example, most, if not all, neocloud customers do not use FP8 training but instead opt for bfloat16 training. The A100 80GB offers far better performance per TCO for small LLMs being trained on bfloat16.
Because Meta’s LLAMA models are driving infrastructure choices for many enterprises and neoclouds, the unit of deployment that is most relevant is the ability to fit Meta’s models. LLAMA 3 405B does not fit on a single H100 node, but does barely fit on an H200 (the model can be quantized, but quality loss is drastic). With 405B already on the edge for H200 HGX servers, the next generation MoE LLAMA 4 will definitely not fit on a single node of Blackwell HGX, dramatically impacting performance per TCO.

As such, a single HGX server will be worse performance/TCO for fine tuning and inference of the most useful open-source models that are driving startup and enterprise deployments. Our estimated pricing for MGX B200A Ultra NVL36 illustrates how HGX B200A is unlikely to sell briskly. Nvidia has multiple strong incentives to cut margin slightly to push MGX because they make it up with higher attach rate of their own networking.
The MGX GB200A NVL36 SKU is a fully air cooled 40kW/rack server that would have 36 GPUs fully interconnected together with NVLink. Per rack, there will be nine compute trays and nine NVSwitch trays. Each compute tray is 2U and contain one Grace CPU and four 700W B200A Blackwell GPUs, compared to the GB200 NVL72 / 36×2, which has two Grace CPUs and four 1200W Blackwell GPUs. For those unfamiliar with the GB200 hardware architecture and component supply chain, see here.

The MGX NVL36 design only has a 1:4 ratio of CPU to GPUs compared to 2:4 ratio in GB200 NVL72 / 36×2. Furthermore, each 1U NVSwitch Tray will just have one switch ASIC, with each switch ASIC having a bandwidth of 28.8Tbit/s.
Since it is only 40kW per rack, the MGX NVL36 can be air cooled. Although most datacenters and current H100 deployments are only 20kW/rack, it is not uncommon to have 40kW/rack H100 deployments too. This is achieved by skipping rows in the datacenter and utilizing cold/hot aisle containment. This same technique can be applied when deploying 40kW MGX NVL36 racks. This makes the MGX NVL36 very easy for existing datacenter operators to deploy without reworking their infrastructure.
Unlike on GB200 NVL72 / 36×2, the higher ratio of four GPUs to one CPU means that it won’t be able to use the C2C interconnects as each GPU would get half as much C2C bandwidth as GB200 NVl72/36×2. Instead, the integrated ConnectX-8 PCIe switch will be leveraged to allow the GPUs to talk to the CPU. Moreover, unlike on all other existing AI servers (HGX H100/B100/B200, GB200 NVL72 / 36×2, MI300), each backend NIC will now be responsible for two GPUs. That means even though the ConnectX-8 NIC design can provide 800G of backend network, each GPU will only have access to 400G of backend InfiniBand/RoCE bandwidth.
On the GB200 NVL72 / 36×2, with ConnectX-8 backend NICs, each GPU would have access to up to 800G of bandwidth.
For the reference design, the GB200A NVL36 will use one Bluefield-3 frontend NIC per compute tray. This is a more reasonable design as compared to having two Bluefield-3 per compute tray for the GB200 NVL72 / 36×2. Even for the MGX NVL36, we still feel that many customers will not opt to use any Bluefield-3, but instead opt to use their own internal NIC in the case of hyperscalers or use a generic frontend NIC like a ConnectX-6/7.
The heart of the GB200 NVL72/NVL36x2 compute tray is the Bianca board. The Bianca board contains two Blackwell B200 GPUs and a single Grace CPU. Each Compute tray has two Bianca board which means there are two Grace CPU and four 1200W Blackwell GPUs in total per compute tray.
On the MGX GB200A NVL36, the CPU and GPUs would be on different PCBs, similar to the design for HGX servers. Unlike HGX servers, we believe that the 4 GPUs per compute tray will be subdivided up into two 2-GPU boards. Each 2-GPU board will have Mirror Mezz connectors similar to the Bianca board. These Mirror Mezz connectors will be used to connect to the ConnectX-8 mezzanine board which connects a ConnectX-8 ASIC with its integrated PCIe switch to the GPUs, local NVMe storage, and Grace CPU.
By having the ConnectX-8 ASICs extremely close to the GPUs, that would mean there is no need for retimers between the GPU and the ConnectX-8 NIC. This is unlike the HGX H100/B100/B200 which requires retimers to go from the HGX baseboard to the PCIe switch.
Since there is no C2C interconnect between the Grace CPU and the Blackwell GPUs, the Grace CPU is also on a completely separate PCB called a CPU motherboard. This motherboard will contain the BMC connectors, the CMOS battery, the MCIO connectors, etc.
The NVLink bandwidth per GPU will be 900Gbyte/s per direction which is the same as GB200 NVL72 / 36×2. On a per FLOP basis, this is a dramatic increase in GPU to GPU bandwidth, which makes MGX NVL36 favorable for certain workloads.
Since there is only 1 tier of switches to connect 36 GPUs, only 9 NVSwitch ASICs are required to provide the non-blocking networking. Furthermore, since there is only one 28.8Tbit/s ASIC per 1U switch tray, it is quite easy to air cool. 25.6Tbit/s 1U switch like the Quantum-2 QM9700 already are easily cooled with air. While Nvidia could have enabled a NVL36x2 design by keeping the switch trays with 2 NVSwitch ASICs, that would increase costs, and would make it potentially impossible to air cool due to the front OSFP NVLink cages blocking airflow.
On the backend network, since there are only two 800G ports per compute tray, we believe that it will be using 2-rail optimized end of row networking. For every eight racks of GB200A NVl36, there will be two Quantum-X800 QM3400 switches.
We estimate that at 700W per GPU, the GB200A NVL36 will most likely be around 40kW per rack. The 2U compute trays will require about 4kW of power, but air cooling 4kW of heat dissipation per 2U space will require specially designed heatsinks and high-speed fans.
We will discuss the cooling challenges of this later in the article, but it is a significant risk for Nvidia on the MGX NVL36 design.
For GB200 NVL72 / NVL36x2, the only customer not using the Connect-X 7/8 backend NICs is Amazon. As discussed in our GB200 architecture analysis, this has already posed a significant engineering challenge as there will be no ConnectX-7/8 or Bluefield-3 present, both of which have integrated PCIe switches. As such, dedicated PCIe switches from Broadcom or Astera Labs are required to connect the backend NICs to the CPU, the GPU, and to local NVMe storage. This consumes additional power and increases BoM costs.
In the SemiAnalysis GB200 Component & Supply Chain Model, we break down all components supplier’s share, volume, and ASP including the PCIe Switch. Since the GB200A NVL36 is completely air cooled, having a dedicated PCIe switch in addition to PCIe form factor NICs at the front of the 2U chassis would add significantly to the thermal engineering challenges.
Therefore, we believe that it will be basically impossible for anyone to do custom backend NICs on GB200A NVL36.
Since the Grace CPUs and the Blackwell GPUs is on a separate PCB, we believe there could be an x86 + B200A NVL36 version too. Since a lot of the ML dependencies are compiled and optimized for x86 CPUs, this could be an added benefit for this SKU. Furthermore, the x86 CPU platform offers higher peak performance CPUs compared to Grace. Unfortunately, there will be thermal challenges for OEMs willing to offer the x86 version as CPUs use about 100 Watts more power. We believe even if Nvidia offers this an x86 B200A NVL36 solution, they will be pushing most customers towards the GB200A NVL36 solution since it can sell the Grace CPU.
The key selling point of the GB200A NVL36 is that it a 40kW per rack air cooled system. The main attraction to customers is that many are still not able to support the liquid cooling and power infrastructure required for the ~125 kW per rack GB200 NVL72 (or 36×2 for more than 130kW across two racks).
The absence of any liquid cooling means that compared to the GB200 NVL72 / 36×2, the thermal solutions will simplify the overall thermal solution essentially back down to a heatsink (3D Vapor Chamber, 3DVC) and some fans. However, given the GB200A NVL36’s compute trays are utilizing a 2U chassis, the 3DVC design will need to be adjusted heavily.
The H100, with a TDP of 700W, currently uses a 4U tall 3DVC, and the 1000W H200 uses a 6U tall 3DVC. In contrast, the MGX B200A NVL36 at 700W of TDP in a 2U chassis is quite constrained. We think a heatsink that expands horizontally in a balcony-like shape so as to increase the surface area of the heatsink will be required.
Besides the larger heatsink required, the fans will need to supply much greater airflow than the fans for the GB200 NVL72 / 36×2 2U compute tray or HGX 8 GPU designs do. We estimate that out of the 40kW rack, 15% to 17% of total system power will be allocated towards internal chassis fans. As a result of this, the TUE number, a metric that better represent energy efficiency gain between air-cooling and liquid cooling, would be much higher for GB200A NVL36 compared to GB200 NVL72 / NVL36.
Even for air cooled servers such as an HGX H100, we believe the fans only consume 6% to 8% of total system power. This is a dramatically less efficient design due to the huge amount of fan power required to make MGX GB200A NVL36 work. Furthermore, there is the potential that even this design may not work, and Nvidia would then have to go back to the drawing board and try to make a 3U compute tray or reduce the NVLink world size.
Before moving on to the hardware subsystem and components changes of the GB200A NVL36, changes that affect numerous players in the supply chain, lets first discuss the GB200A NVL64.
Before Nvidia landed on the MGX GB200A NVL36, they were also experimenting with an air cooled NVL64 rack design as well. This fully air cooled 60kW rack would have had 64 GPUs fully interconnected together with NVLink. We conducted an extensive engineering analysis of this proposed SKU, and due to the various concerns discussed below, we believe this product is not feasible and will not ship.
In the proposed NVL64 SKU, there are 16 compute trays and 4 NVSwitch trays. Each compute tray is 2U and contains one Grace CPU and four 700W Blackwell GPUs, just like the MGX GB200A NVL36. The switch NVSwitch Tray is where major modifications are made. Instead of reducing GB200’s two NVSwitch per tray to one NVSwitch per tray, Nvidia experimented with increasing it to four switch ASICs.
Although the proposed design from Nvidia said that the NVL64 would be a 60kW rack, we have estimated the power budget and think the lower bound is closer to 70kW per rack. Either way, cooling 60kW or 70kW per rack with just air is insane, often requiring rear door heat exchangers, but that destroys the point of an air cooled rack architecture because there are still dependencies on the liquid cooling supply chain and this solution still requires facility level modifications for most datacenters in order to deliver facility water to the rear door heat exchangers.
Another thermal issue that is highly problematic is that NVSwitch Tray would have four 28.8Tbit/s Switch ASICs in a single 1U chassis, requiring nearly 1,500 W of heat dissipation. 1,500W for a 1U chassis isn’t insane on its own, but it is once you consider cooling challenges due to the Ultrapass flyover cables from the switch ASIC to the backplane connectors blocking a lot of the air flow.
Given the air cooled MGX NVL rack is coming to market at breakneck speed, with Nvidia trying to ship product within just 6 months from start of design, engineering a new switch tray and supply chain is quite difficult for an industry operating with already stretched engineering resources.
Another major concern for the proposed GB200A NVL64 is there would be a mismatch of ports between each rack having 64 800G backend ports but with each XDR Quantum-X800 Q3400 switch having 72 800G downstream ports. This would mean that having a rail optimized backend topology would waste ports, with each switch having an extra 16 800G ports sitting empty. Having empty ports on an expensive backend switch hurts the network perf/TCO considerably because switches are expensive, particularly high-radix modular switches such as the Quantum-X800.

Furthermore, 64 GPUs within the same NVLink domain is not ideal. On the surface, this might sound great due to the nice even multiple of two – ideal for different parallelization configs like (Tensor Parallelism TP=8, Expert Parallelism EP=8), or (TP=4, Fully Sharded Data Parallel FSDP=16). Unfortunately, due to the unreliability of the hardware, Nvidia recommends that at least one compute tray per NVL rack be kept in reserve to allow for GPUs to be taken offline for maintenance and thus for use as a hot spare.
If you don’t have at least one compute tray per rack on hot standby, the blast radius of even a single GPU failure on the rack would result in the whole rack being forced to be taken out of service for considerable time. This is similar to how on an 8-GPU HGX H100s servers, a failure of just one GPU on the server will force all 8 H100s to be taken out of service and unable to continue contributing towards the workload.
Reserving at least one compute tray for use as a hot spare leaves each rack with only 60 GPUs contributing towards a workload. While 64 is a nicer number to work with as it has 2, 4, 8, 16, and 32 as common factors, allowing for nicer combinations of parallelism, 60 is not.
This is why the choice of 72 GPUs in total on GB200 in either the NVL36*2 or NVL72 configuration is very deliberate – it allows two compute trays on hot standby leaving users with 64 GPUs per rack contributing towards a workload.
The GB200A NVL36 can have one compute tray on hot standby and have 2, 4, 8, 16 as common factors for parallelism schemes, and therefore enable greater reliability in real workloads.
In the section below we will discuss the impacts to OEMs, ODMs, and components from the delays to the original Blackwell introduction of the MGX GB200A. We expect fewer shipments / pushout of GB200 NVL72 / 36×2 and a dramatic reduction in volume for B100 & B200 HGX. Instead, we expect more shipments of Hopper in 4Q 2024 to 1Q 2025. Furthermore, there will be a shifting of orders for GPUs shipping in the second half from HGX Blackwell & GB200 NVL36x2 to MGX GB200A NVL36.
This will impact all the ODMs and component suppliers as shipment/revenue schedules shift dramatically in 3Q 2024 to 2Q 2025. The magnitude of the impact to each supplier also depends on whether the supplier is a winner or loser from GB200 NVL72 / 36, MGX NVL36, and if they have strong share in Hopper series (and thus benefit from longer Hopper lifecycle).
Component impacts include cooling, PCB, CCL, substate, NVLink copper backplane content, ACC cable content, optic content, BMC, power content, and more. We will compare the BOM cost of MGX GB200A NVL36 system to that of the GB200 NVL72 / 36×2 as this a more apples to apples comparison of the Oberon platform rack system components. This comparison requires understanding the prior post on hardware and component architecture to follow along fully on the incremental change.
In addition, we have updated our GB200 Component & Supply Chain Model with specific ASP, BOM, and our dollar content share estimates for the MGX GB200A NVL36.

